

AV1 is a new general-purpose video codec developed by the Alliance for Open Media. The alliance began development of this new codec using Google's VPX codecs, Cisco's Thor codec, and Mozilla's/Xiph.Org's Daala codec as starting point. AV1 leapfrogs the performance of VP9 and HEVC, making it a next-next-generation codec. The AV1 format is and will always be royalty-free with a permissive FOSS license.
Those of you who followed Daala development know that when the Alliance for Open Media formed, Xiph and Mozilla submitted our Daala codec as one of the inputs toward standardization. Along with Daala, Google submitted its VP9 codec, and Cisco submitted Thor. The idea was to build a new codec out of pieces of all three, along with any other useful research we found. I hadn't written any new demo pages about new tech in Daala or AV1 since then; for a long time we had little idea of what the final codec was going to look like.
About two years ago, AOM voted to base the fundamental structure of the new codec on VP9, rather than Daala or Thor. AOM member companies wanted the shortest path to shipping a useful codec without royalty or licensing strings, and VP9 was decided to be the lowest-technical-risk choice. I agree with that choice; Daala was a contender, but I also think both the lapping approach and frequency-domain techniques required by Daala weren't (and still aren't) mature enough for deployment. There were still technical unknowns in Daala, and choosing VP9 as a starting point avoided most of them.
As a result of starting with VP9, AV1 (the AOM Video Codec 1) is a mostly familiar codec built along traditional block-based transform coding lines. Of course, it also includes new exciting things, several of which are taken from Daala! Now that we're rapidly approaching the final spec freeze, it's time to write more of the long-delayed codec technology demos in the context of AV1.
Chroma from Luma prediction (CfL for short) is one of the new prediction techniques adopted by AV1. As the name implies, it predicts the colors in an image (chroma) based on brightness values (luma). Luma values are coded and decoded first, and then CfL makes an educated prediction of the colors. When the guess is good, this reduces the amount of color information to be coded, saving space.
CfL is not actually brand new in AV1. The seminal CfL paper dates from 2009, and LG and Samsung jointly propsed an early implementation of CfL named LM Mode that was rejected during the design of HEVC. You'll remember I wrote about the particularly advanced version of CfL used in the the Daala codec. Cisco's Thor codec also had a CfL technique similar to LM Mode, and HEVC eventually added an improved version called Cross-Channel Prediction (CCP) via the HEVC Range Extension.
| LM Mode | Thor CfL | Daala CfL | HEVC CCP | AV1 CfL | |
|---|---|---|---|---|---|
| Prediction Domain | spatial | spatial | frequency | spatial | spatial |
| Coding | none | none | sign bit | index + signs | joint sign + index |
| Activation Mechanism | LM_MODE | threshold | signal | binary flag | CFL_PRED (uv-only mode) |
| Requires PVQ | no | no | yes | no | no |
| Decoder modeling? | yes | yes | no | no | no |
Above: A summary of the characteristics of various Chroma from Luma (CfL)implementations.
LG's LM Mode and Thor were similar in that the encoder and decoder both run an identical prediction model in parallel, and do not need to code any parameters. Unfortunately, this parallel/implicit model reduces fit accuracy and increases decoder complexity.
Unlike the others, Daala's CfL worked in the frequency domain. It signaled only an activation and sign bit, with the other parameter information already implicitly encoded via PVQ.
The final AV1 CfL implementation builds on the Daala implementation, borrowing model ideas from Thor and improving on both through additional new research. It avoids any complexity increase in the decoder, implements a model search that also reduces encoder complexity over its predecessors, and notably improves the encoded model fit and accuracy.
At a fundamental level, compression is the art of prediction. Until the last generation or so, video compression focused primarily on inter-frame (or just inter) prediction, that is, coding a frame as a set of changes from other frames. Frames that use inter-frame prediction are themselves collectively referred to as inter frames. Inter-frame prediction has become fantastically powerful over the past few decades.
Despite the power of inter-prediction, we still need occasional
standalone keyframes. Keyframes, by definition, do not
rely on information from any other frames; as a result, they can
only use intra-frame (or just intra) prediction that works
entirely within a frame. Because keyframes can only use
intra-prediction, they are also often referred to
as intra frames. Intra/Keyframes make it possible to seek
in a video, otherwise we'd always have to start playing at and
only at the very beginning*.
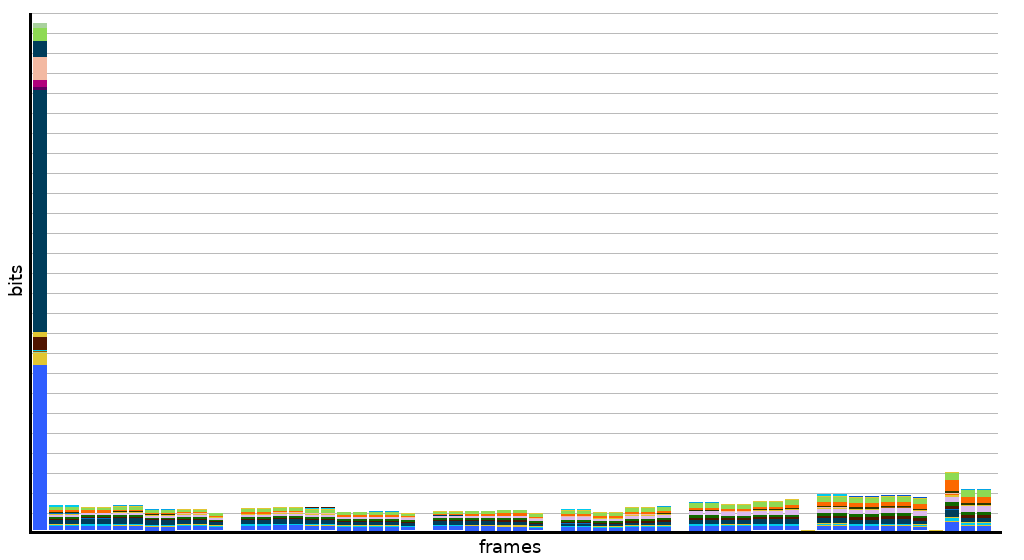
Compared to inter frames, keyframes are enormously large, so they tend to be used as seldom as possible and spaced widely apart. Despite this, as inter frames have gotten smaller and smaller, keyframes have taken up an increasingly large proportion of a bitstream. As a result, video codec research has looked for newer, more-powerful forms of intra-prediction to shrink keyframe size. And, despite their name, inter frames can also use intra-prediction techniques in those cases where it's beneficial.
Improved intra-prediction is a double win!
Chroma from Luma works entirely from luma blocks within a frame, and thus is an intra-prediction technique.
What makes us think we can predict color based on brightness?
Most video representations reduce channel correlation by using a YUV-like color space. Y is the luma channel, the grayscale version of the video signal made by adding together weighted versions of the original red, green and blue signals. The chroma channels, U and V, subtract the luma signal from blue, and the luma signal from red respectively. YUV is simple and substantially reduces coding redundancy across channels.

And yet, it's obvious looking at YUV decompositions of frames that edges in the luma and chroma planes still happen in the same places. There's remaining correlation that we can exploit to reduce bitrate; let's try to reuse some more of that luma data to predict color.
Chroma from Luma prediction is, at its heart, the process of colorizing a monochrome image based on educated guessing. It's not unlike taking an old black-and-white photo, some colored pencils, and getting to work coloring in the photo. Of course, CfL's color predictions must be accurate to be useful; they can't be wild guesses.
This work is made easier by the fact that modern video codecs break an image down into a hierarchy of smaller units, doing most of the encoding work on these units independently.

A model that predicts color across the entire image at once would be unwieldy, complex, and error-prone, but we don't need to predict the entire image. Because the encoder is working with small chunks at a time, we only need to look at correlations over small areas, and over these small areas, we can predict color from brightness with a high degree of accuracy using a fairly simple model. Consider the small portion of the image below, highlighted in red:

Over this small range for this example, the correct 'rule' for coloring the image is simple: Brighter areas are green, and color desaturates along with brightness down to black. Most blocks will have similarly simple coloration rules. We can get as fancy as we like, but simple also works very well, so let's start with simple and fit the data to a simple αx+β line:

Well, OK, it's two lines-- one for the U channel (Blue difference, Cb) and one for the V channel (Red difference, Cr). In other words, where Lrij are the reconstructed luma values, we compute the chroma values as follows:
| Uij | = | αULrij + | βU |
| Vij | = | αVLrij + | βV |
What do these parameters look like? The αs select a specific hue (and anti-hue) from a 2D plane of choices that will be scaled/applied according to the luma:

The βs alter the zero-crossing point of the color scale, that is, they're the knobs that shift the minimum and maximum levels of colorization applied. Note that β allows us to apply negative color as well; that gives us the opposite of the hue selected by α.
Our task now boils down to choosing the correct αs and βs, and then encoding them. Here's one straightforward implicit approach from Predicting Chroma from Luma in AV1:
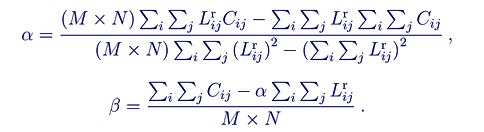
That looks scarier that it is. In English: Perform a least squares fit of the chroma values versus the reconstructed luma values to find α, then use α to solve for the chroma offset β. At least, this is one possible way to handle the fit, and it's often used in CfL implementations (such as LM Mode and Thor) that do not signal either α or β. In this case, the fit is made using already decoded chroma values of neighboring pixels that have already been fully decoded.
Daala performs all prediction in the frequency domain, CfL included, providing a prediction vector as one of the inputs to PVQ encoding. PVQ is a gain/shape encoding; the luma PVQ vector encodes the location of the shapes and edges in luma, and we simply re-use it as a predictor of the shapes and edges in chroma.
Daala does not need to encode an α value, as that's subsumed into the PVQ gain (except for the sign). Nor does Daala need to encode a β value; because Daala applies CfL only to the AC chroma coefficients, β is always zero. This reinforces an insight: β is conceptually just the chroma values' DC-offset.
In effect, because Daala uses PVQ to encode transform blocks, it gets CfL almost for free, both in terms of bit cost and computational cost in the encoder as well as the decoder.
AV1 did not adopt PVQ, so the cost of CfL is approximately equal whether CfL is computed in the pixel or frequency domain; there's no longer a special bonus to working in frequency. In addition, TF (Time-Frequency resolution switching), which Daala uses to glue the smallest luma blocks together to make subsampled chroma blocks large enough, currently only works with the DCT and Walsh-Hadamard transforms. As AV1 also uses the discrete sine transform and a pixel domain identity transform, we can't easily perform AV1 CfL in the frequency domain, at least when we use subsampled chroma.
But unlike Daala, AV1 doesn't need to do CfL in the frequency domain. So, we move Daala's frequency-domain CfL back into the pixel domain for AV1. One of the neat things about CfL is that the basic equations work the same way in both domains.
CfL in AV1 must keep reconstruction complexity to a minimum. For this reason, we explicitly code α so that there is no expensive least-squares fitting in the decoder. The bit cost of explicitly coding α is more than outweighed by the additional accuracy gained by computing it using the current block's chroma pixels as opposed to neighboring reconstructed chroma pixels.
Next, we optimize the fitting complexity on the encoder-side. In Daala, which operates in the frequency domain, we perform CfL using only luma's AC coefficients. AV1 performs CfL fitting in the pixel domain, but we can subtract the average (that is, that already-computed DC value) from each pixel, rendering the pixel values zero-mean and equivalent to the AC coefficient contribution as in Daala. Zero-mean luma values cancel out a substantial portion of the least-squares equation, greatly reducing the computational overhead:
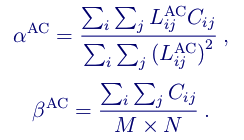
There's more we can do. Remembering that β is simply chroma's DC-offset, we realize that the encoder and decoder already perform DC-prediction for the chroma planes as it's needed for other prediction modes. Of course, a predicted DC value is not going to be as accurate as an explicitly coded DC/β value, but testing shows that it's still quite good:
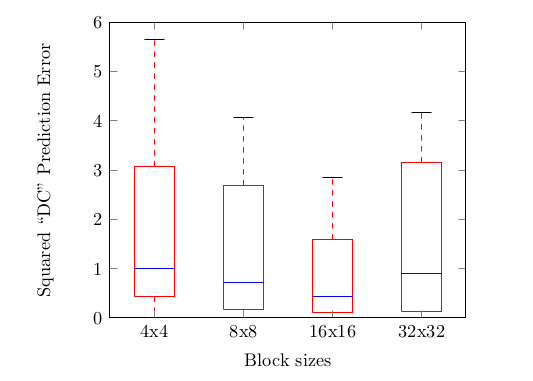
As a result, we simply use the pre-existing chroma DC prediction instead of β. This not only means we don't need to explicitly code β, it also means we do not need to explicitly compute β from α in either the decoder or encoder. Thus, our final CfL prediction equation becomes:
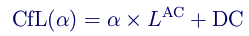
In those cases where prediction alone isn't accurate enough, we encode a transform-domain residual. And, of course, when the prediction isn't good enough to save any bits at all, we simply don't have to use it.
CfL gains are, like any other prediction technique, dependent on the test. AOM uses a number of standardized test sets hosted at Xiph.Org, and made available through the automated 'Are We Compressed Yet?' testing tool.
CfL is an intra-prediction technique, and to best isolate its usefulness in intra-coding, we can look at its performance on keyframes using the 'subset-1' image test set:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Average | -0.53 | -0.31 | -0.34 | -4.87 | -12.87 | -10.75 | -0.34 |
Most of the metrics here are not color-sensitive, they're simply included because they're always included and it's nice to see CfL doesn't damage them. Of course, it shouldn't; by making color coding more efficient, it is also freeing up bits that can be used to better represent luma as well.
That said, CIE delta-E 2000 is the metric to pay attention to; it implements a perceptually-uniform color error metric. We see that CfL saves nearly 5% in bitrate when both luma and chroma are considered! That's a stunning number for a single prediction technique.
CfL is available for intra-blocks within inter-frames as well. During AV1 development, the objective-1-fast set was the standard test set for metric evaluation of motion sequences:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Average | -0.43 | -0.42 | -0.38 | -2.41 | -5.85 | -5.51 | -0.40 |
| 1080p | -0.32 | -0.37 | -0.28 | -2.52 | -6.80 | -5.31 | -0.31 |
| 1080p-screen | -1.82 | -1.72 | -1.71 | -8.22 | -17.76 | -12.00 | -1.75 |
| 720p | -0.12 | -0.11 | -0.07 | -0.52 | -1.08 | -1.23 | -0.12 |
| 360p | -0.15 | -0.05 | -0.10 | -0.80 | -2.17 | -6.45 | -0.04 |
As expected, we still see solid gains, though CfL's contribution is watered down somewhat by the preponderance of inter-prediction in use. Intra blocks are used primarily in keyframes, each of these test sequences coded only a single keyframe, and intra-coding is not used often in inter-frames.
The big exception is '1080p-screen' content where we see a whopping 8% rate reduction. This makes sense; most screencasting content is fairly static, and where areas change they are almost always wholesale updates suited to intra coding rather than the smooth motion suited to inter. These screencasting clips code more intra blocks and so see more gain from CfL.
This is true of synthetic and rendered content as well:
| BD-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Twitch | -1.01 | -0.93 | -0.90 | -5.74 | -15.58 | -9.96 | -0.81 |
The Twitch test set is entirely live-streamed video game content, and we see solid gains here as well.
Chroma From Luma is not, of course, the only technique being adopted in a production codec for the first time in AV1. Next post we'll look at a technique that really is entirely brand new in AV1: The Constrained Directional Enhancement Filter.
—Monty (monty@xiph.org, cmontgomery@mozilla.com) April 9, 2018* It's also possible to spread a keyframe through other frames using a technique called rolling intra. Rolling intra splits standalone keyframes into standalone blocks that are sprinkled through preceding inter frames. Rather than seeking to a keyframe and simply beginning playback at that point, a rolling intra codec seeks to an earlier point, reads forward collecting the standalone keyframe pieces that are spread out through other frames, then begins playback after it has enough information to construct a complete, up-to-date frame. Rolling intra does not improve compression; it merely spreads out bitrate spikes caused by large keyframes. It can also be used as a form of error resiliency.
†Technically, Energy is Power x Time. When comparing apples and oranges, it is important to express both in watt-hours.
