
One of the hardest aspects of the current Theora spec to work around has been the 'many-small-passes' design. In the original encoder and the original design concept, each stage and facet of analysis/coding is done in a seperate complete pass through the frame data. Each specific derived set of data is coded in its own segment, such that first all the bitflags that define which blocks are coded for the full frame is written to the bitstream, then all the mode flags that specific thec coding modes for all the macroblocks for the whole frame are written to the bitstream, then all the motion vectors for all the macroblocks for the whole frame are written to the bitstream and so on. In the original encoder, over seventy complete passes are made through each video frame.
On a modern processor, this spells near complete disaster for the data cache; we estimate that the encoder spends more time in cache stall than actually processing. It also increases the need for temporary storage as data generated from one pass but needed by another must be stored somewhere. For example, the mainline Theora encoder stores six complete copies of each frame of video data in various stages of decomposition/recomposition. Two of these frame copies are mandated by the spec (the output reconstruction frame and the 'golden frame'), the rest are merely artifacts of the 'many small passes' design making more efficient memory usage exceedingly difficult.
Difficult but not impossible. It requires advanced cleverness which a more modern design would not require, nevertheless the end result can be nearly equal with only the cost of the cleverness effort expended.
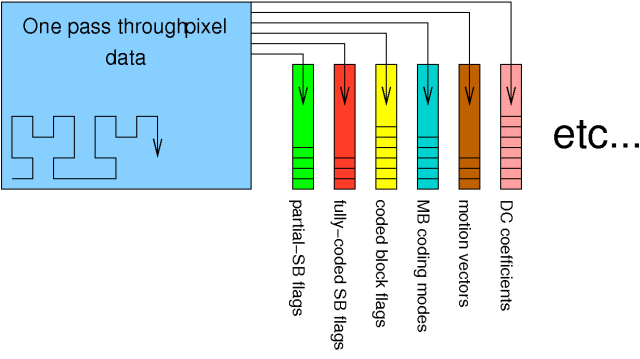
The Theora format writes out each category of data in a contiguous stream of tokens before moving onto encoding the next category. In order to make a single analysis pass through the uncompressed video data, it's necessary to accumulate data tokens into multiple token stacks.
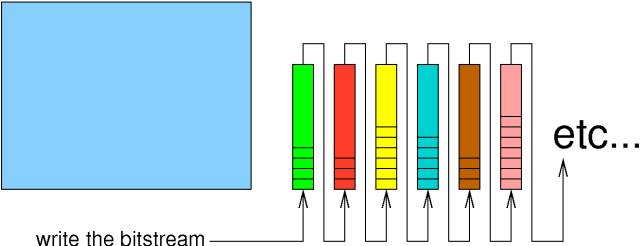
Once the pass through the uncompressed data is completed, each stack of accumulated tokens is written to the bitstream in turn.
Naturally, the devil is in the details. There are two fundamental problems: passes that rely on some complete result of a preceeding pass, and differing scan ordering from pass to pass.
Because multiple passes had apparently always been part of the intended codec design, the original designers saw fit to use whatever frame block ordering for a pass that was most convenient or most advantageous to that particular pass. Some passes through the data occur in raster order. Some passes are in Hilbert order. Some passes are in a mix of the two. For example, motion vectors are coded by macroblock in Hilbert order, but are coded within the macroblock in raster order. The blocks themselves are always coded by superblock in Hilbert order. This means, that the blocks are coded in one order, but the motion vectors for those same blocks are in an entirely different order. Last but not least, in non-4:4:4 video, because the blocks are coded by superblocks and the superblocks in the three pixel planes are the same number of 8x8 blocks despite the differning plane sizes, the blocks and macroblocks of the Y, Cb and Cr planes are also not coded in the same order.
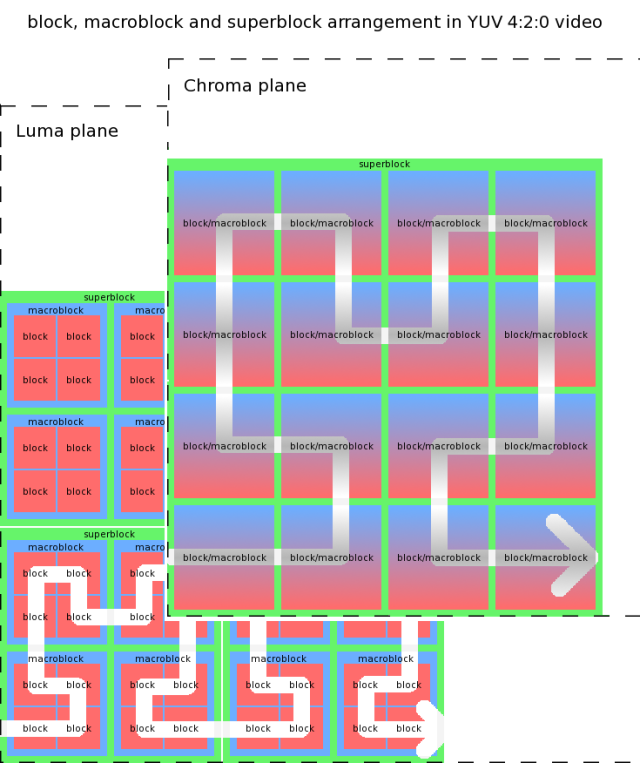
Theora block, macroblock, and superblock arrangement in YUV 4:2:0 luma and chroma planes.
In fact, the possible number of ordering mixtures is nearly fully realized. This means that even though we could potentially make a single data pass through the video frame and simply store the coded data in multiple 'stacks' that simulate multiple passes, we can't do so directly because each stack is coded by taking a different path through the same pixel data.
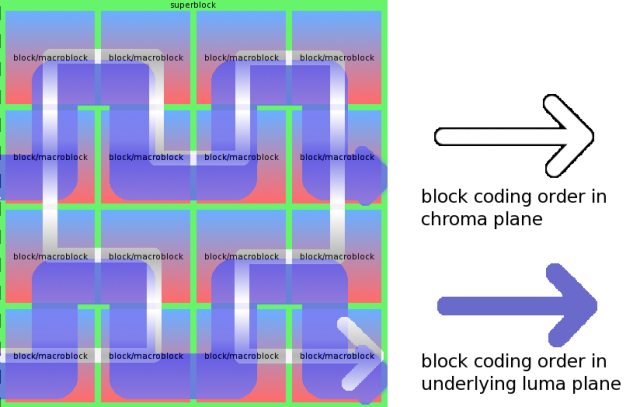
Hilbert coding order in luma and chroma planes for 4:2:0 video
....and that's all childs' play compared to the interactions between DCT zero-run coding, DCT EOB-run coding and DC prediction.
The biggest reason to perform analysis, transform, quantization and tokenization in one pass is to allow efficient per-token rate-distortion optimization. This is a powerful technique and the biggest 'modern' feature lacking in the Theora encoder. In the current scheme where all analysis must be completed before tokenization can begin, we'd need to use two full frames worth of temporary storage data. In addition, other aspects of analysis would not be able to make use of the information produced by the per-token analysis, reducing the effectiveness of other parts of the rate-distortion analysis. The biggest hurdle to jump for analyzing and coding DCT blocks in one pass is indirectly caused by Theora's DC prediction combined with its DCT coding scheme.
We can't code the DC components before DC prediction. To perform DC prediction, it's necessary to have already determined the skip blocks, motion vectors and block modes, as well as computed the DC component of the DCT blocks for all blocks in the frame. DC prediction can't be performed 'on the fly' because it's performed in raster order, and the DCT blocks are coded in Hilbert order. However, the Theora coding scheme requires that the DC component of each block is coded before any of the other components. This makes two passes in some form entirely unavoidable. What we can do is make the complexity and memory footprint of the second pass as trivial as possible.
Theora encodes DCT blocks by grouping the coefficients together. All DC values are coded first, all AC coefficient 1s are coded next and so on. However, the structure is more complex where zeros are concerned. Because zeros are by far the most common value, zeros are not coded as independent tokens, but rather grouped in runs that may also include a nonzero value at the end. If the DC and first two AC values in a block are zeros and the third AC value is a 1, then the encoded token represents the value string [0, 0, 0, 1]. It is encoded in the DC position and then the next three coefficients are 'skipped' (no token written to their stacks). Coding resumes with AC token 4.
When all the remaining coefficients in a block are zeros, that results in an End Of Block token. EOBs are grouped into runs across blocks. In effect, DCT coding is an intertwined two dimensional structure, where removing, omitting or modifying a token will usually modify the entire subsequent coding structure. Changes are not restricted to one block or one coefficient group; any single omission affects all coefficient coding groups of all subsequent blocks.
This means we can't simply have 64 token stacks, and delay coding DC until after the rest of the coding is complete. Pull the DC token out (or omit it) and it is exceptionally difficult to put the resulting collapsed tetris jumble back together. Difficult... but not impossible.
Cut to whiteboard for the local talk... I'm sick of fighting drawing programs tonight...
Additional note: There's also the possibility of chunk-vectorizing in which we find the lowest-common-denominator of the path followed by Hilbert ordering and raster ordering in the same plane, and process groups of scanlines in two passes in groups of this lowest common denominator. This also does not avoid the second pass, but can further reduce the temporary storage requirement to link the passes together. The code complexity for this further step may or may not be worth the performance gain-- for now, I'm assuming not. The mainline decoder implements this strategy.
The original Theora critique document lists a number of Theora performance/efficiency problems that were split between inadequacies the encoder and inadequacies in the bitstream format. The first stage of the new Thusnedla encoder was to correct the inadequacies that could be blamed entirely on the encoder before considering improvements to the format itself.
We review here the items on the original 'problem' list that can be blamed solely on the encoder and gauge the progress of the last six months of development.
VP3 is known for detail loss due to overly aggressive high frequency component quantization. Even at the highest bitrates, fine features are noticably softened. This is due to VP3 adopting and hardwiring the example quantization matrix provided in the original JPEG image format specification which exaggerates detail loss.
Although Theora removes the hardwired quantization matrix, the Theora encoder has continued to use the original VP3 quantization matrix. This is a serious image quality liability.
status: Pending. This is one of the easier problems to tackle, but will not be addressed until the rate-distortion optimization is substantially implemented. Altering the quantization matrix changes before RD is in place makes it harder to directly observe and refine the benefits of RD in isolation (altering the quantization matricies requires retaining several internal metrics, so switching back and forth is not a trivial task). RD optimization is a far the harder task (with greateser overall anticipated benefits), so RD is being implemented first.
The bitrate manager as implemented in VP3 and carried into Theora is swift to anger, buggy, and largely responsible for the atrocious quality of managed-rate streams.
status: Inplemented but not active/debugged. Bitrate management in the new decoder is implemented as an operation mode of the overall rate-distortion optimization engine. This part of the code is written but not functional because an underlying piece of the RD optimization engine it relies upon (adaptive qi selection based on rho-domain analysis) is not working correctly yet.
Although the artifacts I'd referred to were a bitstream limitation issue, it also turns out that updates and improvements to the motion compensation analysis greatly improved MV efficiency and reduced perceived MV artifacts even in the context of Theora's current motion vector system.
status: Complete to the extent that can be realized in stage 1
The original document describes inefficient coding both in terms of a somewhat outdated semantic-token coding design as well as inefficient use of that design. We cannot replace the tokenization design in stage 1, but we can correct its inefficient usage in terms of both computational complexity and bit usage efficiency.
status: Both aspects have been substantially addressed, although the results of bitrate efficiency improvements are backloaded. MV and mode selection improvements are complete. The structural changed discussed in the beginning of the document are about to realize full per-token optimization, the single greatest expected improvement the encoder will see in stage 1.