

The Vorbis codec is more than halfway through its approximate intended lifetime of 20 years or so, and the state of the art in audio coding has improved considerably since Vorbis's introduction. Xiph has been developing two new, next-generation codecs (Ghost and CELT) as successors to Vorbis. CELT is nearing completion/bitstream freeze. Ghost research was postponed until recently to devote more resources to improving video (see the 'Thusnelda' and 'Ptalarbvorm' encoders).
Ghost development now resumes where it left off in 2007.
...or more properly, "what will it be, we hope?"
First and foremost, Ghost is vapourware. At present it is merely a collection of ideas and some early-stage research. Eventually, it is intended to be a codec that improves upon and supersedes Vorbis in its current niche. The design constraints/requirements are similar to Vorbis:
Ghost intends to improve and expand upon the Vorbis feature set in the following ways:
This first update will give a quick high level sketch of the initial codec game plan, and then dive into the sinusoidal analysis research currently underway.
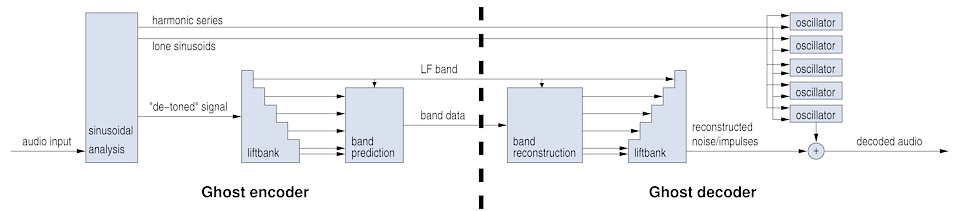
Ghost will be a hybrid tone + noise codec that splits and separately encodes strong sinusoids from the time domain 'toneless' signal. It attempts to abandon the lapped transform techniques that have had a stranglehold on audio codec design for the past 20 years, beginning with MP3 and continuing on to AAC and Vorbis (and CELT).
The dominant bottlenecks in improving Vorbis's coding efficiency are:
Both of these bottlenecks arise from exclusively encoding in the domain of the MDCT, which offers linear frequency resolution and poor time-domain energy compaction. Researchers have implemented many mitigation strategies to give lapped transforms better (acceptable) performance, but it doesn't change the fact that the benefits of lapped Fourier-like transforms have more to do with their mathematical convenience than they do inherent appropriateness to audio coding. Rather than mitigating the shortcomings of the MDCT, we hope to find a more fundamentally appropriate representation.
The core of the Ghost game plan relies on efficient separation of tonal content from the rest of the audio signal. Sinusoids will be encoded parametrically as harmonic structures.
The time-domain audio signal that remains after removing the tonal content will then be passed through a liftbank to divide that signal into roughly bark-aligned time domain subbands. At present, suitable lifting filters exist as an off-the-shelf technology.
Numerous techniques pioneered by CELT, such as the PVQ coding model, band folding, synthetic excitation, and invariant energy preservation are applicable to Ghost, despite the fact that CELT subbands in frequency and Ghost intends to subband in time.

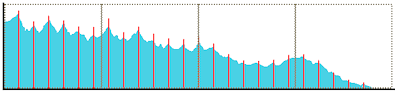

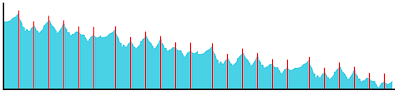
The current Ghost design has an advantage over naive spectral band replication techniques; because the harmonic data is removed from the subbanded signal, folding/replication in Ghost does not need to worry about artifacts resulting from displaced/corrupted harmonic structures.
The first figure at left represents a hypothetical frequency spectrum with strongly harmonic content. In the second, third and fourth figures, the signal is compressed by dividing the spectrum into four bands, transmitting only the lowest band, and and then reconstructing the upper three bands based on that lowest band. Even after parametrically adjusting the energy content and spectral shape in the reconstructed bands, the harmonics are at the wrong frequencies. A codec that does not remove the tonal content before replicating/folding must either live with the resulting artifacts, or employ additional techniques to rotate and adjust frequency positions.

Most of the desired pieces of Ghost have already been pioneered by CELT development, or can be lifted from existing research. The tasks at hand are tasks of integration, not low-level mathematical research. The exception, and thus the hard part, is the sinusoidal analysis and extraction. Many techniques currently exist for analyzing and isolating tonal content from signals, but as yet none are both efficient and reliable enough.
The good news is that we have a start on the problem from our 2007 research (see paper on the right). In addition, the efficiency goal is considerably more aggressive than strictly required; in Vorbis's case, for example, simply adding an additional long-term predictor to assist LF resolution would greatly improve coding efficiency. That said, efficiency of sinusoidal extraction is one area where furthering the state of the art can reap immediate rewards. Ghost's goals are quite ambitious and sinusoidal extraction is the primary area that will determine how close we come to meeting those goals.
Two basic strategies exist for sinusoidal analysis:
For purposes of a research anchor (and because it's the easiest place to start), we begin with a brute force approach to the former.
At left we see unfiltered results from directly applying the Sinusoidal Parameter Estimation algorithm, frame by frame, to unfiltered input audio. The initial sinusoidal guesses are seeded from all local magnitude maxima of a windowed FFT of the frame; window size is 1024 samples. The display shows the lower 1/8th of the full spectrum. The left channel is in red, the right in green. At top is a rolling spectrogram, below are the inputs and output from the sinusoidal estimator. The upper line is the windowed FFT of the input, the circles show the frequency and amplitude of each estimated output frequency to arbitrary precision, and the lower filled area is the result of subtracting the estimated sinusoids from the input audio.
Note that the sinusoidal estimator is neither critically sampled, nor is it restricted to a basis set of evenly spaced sinusoids. It is capable of exactly modeling any input frequency and phase without energy leakage without a window. It is, however, susceptible to modulation and signal noise; both will affect the quality of a fit.
This example run makes no attempt to distinguish high quality (very audible) tones from low-quality tones or noise. it is not a practical approach, but does illustrate the behavior of the sinusoidal estimation. The example also shows that the arbitrary-basis estimation is compacting more energy into individual sinusoids than the fixed-basis FFT, though in nearly all signals substantial noise exists only 20-30dB below even the strongest sinusoids.
Estimation as done above is impractical for two reasons; it's far too slow (wasting computation on too many junk inputs) and does not provide any insight as to the quality or importance of a given tone.
A next obvious step is to extract the the tone masking engine from Vorbis, and use it to both inform initial seeds as well as weed out or add to the sinusoid set in successive iterations.
Cepstral analysis is a rather old (and in some ways obvious) tool from classical speech coding. Data is transformed using an FFT, the FFT amplitudes are converted to log scale and then the FFT of the log scale data is taken, transforming the 'spectrum' into a 'cepstrum'. This technique looks for evenly spaced energy peaks in a spectrum, compacting the fundamental period of the harmonic spacing within the spectrum into a peak in the cepstrum. Sinusoidal Estimation can also be used to polish the fit of cepstral data, just as it can be used to polish the fit of spectral data.
Classic cepstral analysis is used to extract a single fundamental; I'm not sure of the state of the art for using cepstrums to analyze polyphonic input.
The other drawback of the cepstrum is that it can only see harmonic structures; naked tones with no harmonics are invisible to cepstral analysis. Thus it must be paired with some form of auxiliary sinusoidal estimation.
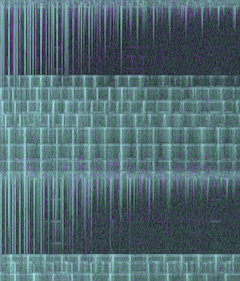
It's not difficult to look at the image to the left and say 'there's lines in that thar thing!' Granted, that's by using our big brains stuffed full of massively parallel image processing hardware.
Regardless, edge and line detection is one of the oldest focuses of image research. Some of this research may be suitable for long-term sinusoidal estimation purposes should simpler techniques prove inadequate.
 Ghost development work is sponsored by Red Hat Emerging Technologies.
Ghost development work is sponsored by Red Hat Emerging Technologies.