

It's worth mentioning surround encoding improvements in 1.1, partly because quite a few people are unaware that Opus even supports surround audio. It does— up to 255 channels, same as Vorbis. Also similar to the early Vorbis releases, surround encoding in Opus 1.0 was mostly untuned. The quality was good, but it was not particularly efficient.
The 1.1 release includes several simple but significant surround encoding upgrades, mostly involving smarter use of bit allocation.
Unlike Vorbis, Opus only supports coupling channels into stereo pairs. Surround streams consist of a collection of stereo and mono substreams bundled together.
Previously, bit allocation in a surround stream was about as simple as possible; every channel got the same number of bits to start, whether it was mono, part of a stereo pair, or LFE. In addition, these assignments were inflexible; channel bit allocation wasn't adjusted according to the content it was carrying. Even an inaudible channel carrying near-silence got the same allocation (though later decision making could effectively turn off channels carrying true digital silence).
Libopus 1.1 uses a better scheme that's still relatively simple. For requested bitrates over 20kbps per channel, every substream (whether it's stereo or mono) gets 20kbit up front. LFE is an exception; it gets 3.5kbps. Below 20kbps/channel, the 20kbit allocation is scaled proportionately. Remaining bits of the base allocation are then evenly divided amongst channels. This means that at at the lowest bitrates, stereo and mono substreams begin with the same base rate. As the overall bitrate increases, stereo substreams receive twice the additional bits of mono streams so that at high rates, stereo substreams asymptotically approach having twice as many bits as mono.
These base allocations are fungible in 1.1. Further content analysis, such as the stereo saving, surround masking, and tonality estimation below then adjust bits allocations between streams based on the audio content.
Opus 1.0 used SILK mode to encode the LFE channel at low rates, and transitioned to CELT mode at higher rates. SILK mode is not capable of as high quality for the LFE as CELT is, however 1.0's CELT mode was unable to encode only the low frequencies efficiently, so SILK mode was used at low rates to save space. Improvements in the encoder infrastructure allow us to use CELT mode with a limited number of bands to improve the encoded quality at low rates, and greatly reduce the LFE channel usage at higher rates.
Surround masking takes advantage of cross-channel masking between free-field loudspeakers. Obviously, we can't do that for stereo, as stereo is often listened to on headphones or nearfield monitors, but for surround encodings played on typical surround placements with listeners placed well within the soundfield, there's considerable savings to be had by assuming freefield masking. We only need to make slight modifications to ensure that the encode still sounds good when downmixed to stereo for playback on non-surround systems.
The first version of the encoder's new cross-channel masking engine appeared in the earlier 1.1 beta release. This 1.1 final release further refines the masking engine to analyze each channel's relative audible contribution within the sound field per critical band, and adjust encoding accordingly. The improved engine plus additional tuning via listening testing means libopus now supports quite usable 5.1 and 7.1 encoding from 45kbps (that's total bitrate, not per-channel), and high quality surround starting at around 128kbps.
|
Bitrate adjustment based on surround masking
|
|
|
total bitrate
|
|
| download these samples: | [ | Tron | | | ...Opus 1.0 | | | ...Opus 1.1 | ] |
| [ | Sita | | | ...Opus 1.0 | | | ...Opus 1.1 | ] |
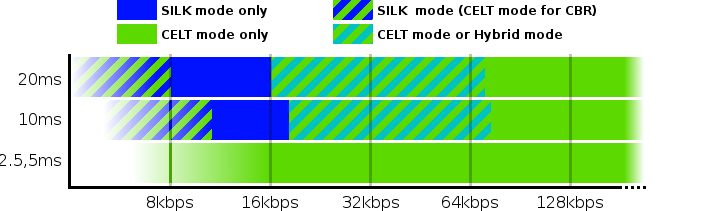
Opus is built from pieces of what began as two separate codecs: the SILK voice codec and the CELT music codec. These were combined into into Opus, a single codec that can draw on the building blocks of each. Internally, Opus can operate in SILK-mode, CELT-mode, or transparently combine the two into hybrid operation.
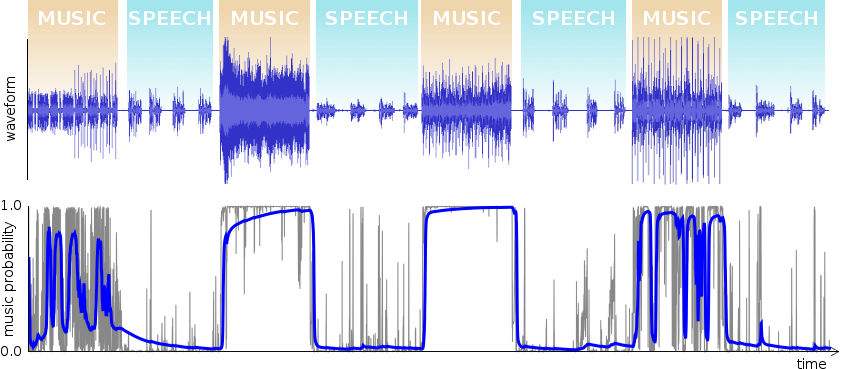
In previous releases, the developer or user needed to manually select the 'speech' or 'music' operating mode to match the audio being encoded for optimal performance. As of 1.1, libopus analyzes the audio content in realtime and dynamically selects the correct encoding mode on the fly.
The speech/music detector in libopus 1.1 has three components; a feature detector, an instantaneous modeler, and a temporal modeler.

The first component is a feature detector that converts the input audio into Bark-frequency cepstral coefficients (BFCC) — similar to the Mel-frequency cepstral coefficients (MFCC) used in speech recognition — along with the coefficients' first- and second-order derivatives. In addition, we also use the tonality estimate we computed for VBR above and several other previously computed metrics.
The statistical modeler is a multi-layer perceptron (MLP), aka neural network. It's worth mentioning that we could have used (and did try) the more usual Gaussian mixture models, but in the end, a neural network worked better. This could be due to the fact that neural networks return a meaningful continuous probability by design, a fundamental requirement for the final probability computation below.
The neural network outputs the probability of the current frame being music given the instantaneous observation at time t. Naturally, this signal is quite noisy and we can assume that it's highly unlikely our input signal would alternate between voice and music every few ms. We model the audio behavior as a Markov model, assuming the probability of transitioning from voice to music (and vice versa) in a given 10ms period is .00005. That works out to a transition once every 200 seconds on average.

A temporal statistical modeler, based on the Markov model, weights and integrates the neural network's instantaneous probability output over time. Finally the encoder compares the integrated probability against a switching threshold that depends on bitrate, bandwidth, frame size, and application to determine the coding mode.
|
Realtime automatic mode switching
|
||||
|
||||
| download these samples: | [ | speech / music test sample (original) | | | ...45kbps Opus | ] |
When operating with a low-latency constraint, Opus has to make decisions without any look-ahead. This makes the decision process harder than it would otherwise be, because we can't look into the future to confirm the correctness of a decision. Fortunately, mode decision errors in Opus tend to be rather 'soft' due to the codec's continuous operating range; incorrect speech-vs.-music decisions nearly always happen where either mode will do a reasonable job, as the demo above shows.
Since the 1.1 alpha, libopus can optionally use lookahead in those applications where ultra-low latency isn't important. This delayed decision mode can, as mentioned above, look forward into buffered audio to make mode selection decisions based not only on past speech-vs.-music probability, but also future speech-vs.-music probability. As such, it is able to make higher-confidence mode decisions slightly sooner. Note that this feature is not yet implemented in opusenc, so no fancy demo... yet.
Opus is a low-delay codec, and uses a shorter MDCT window than non-realtime audio codecs such as Vorbis or AAC. A short MDCT window has higher spectral energy leakage between bins, and this leakage decreases coding efficiency for strong tones. Samples that contain strong tones with a large number of harmonics that stand well above the noise floor are thus especially difficult.
In addition, typical bit allocation schemes (such as used by Opus) reduce the precision of high-frequency bands, a strategy appropriate for the vast majority of audio. If the precision drops too low however, strong harmonics in the upper frequency bands wash out into an indistinct, fuzzy hiss.
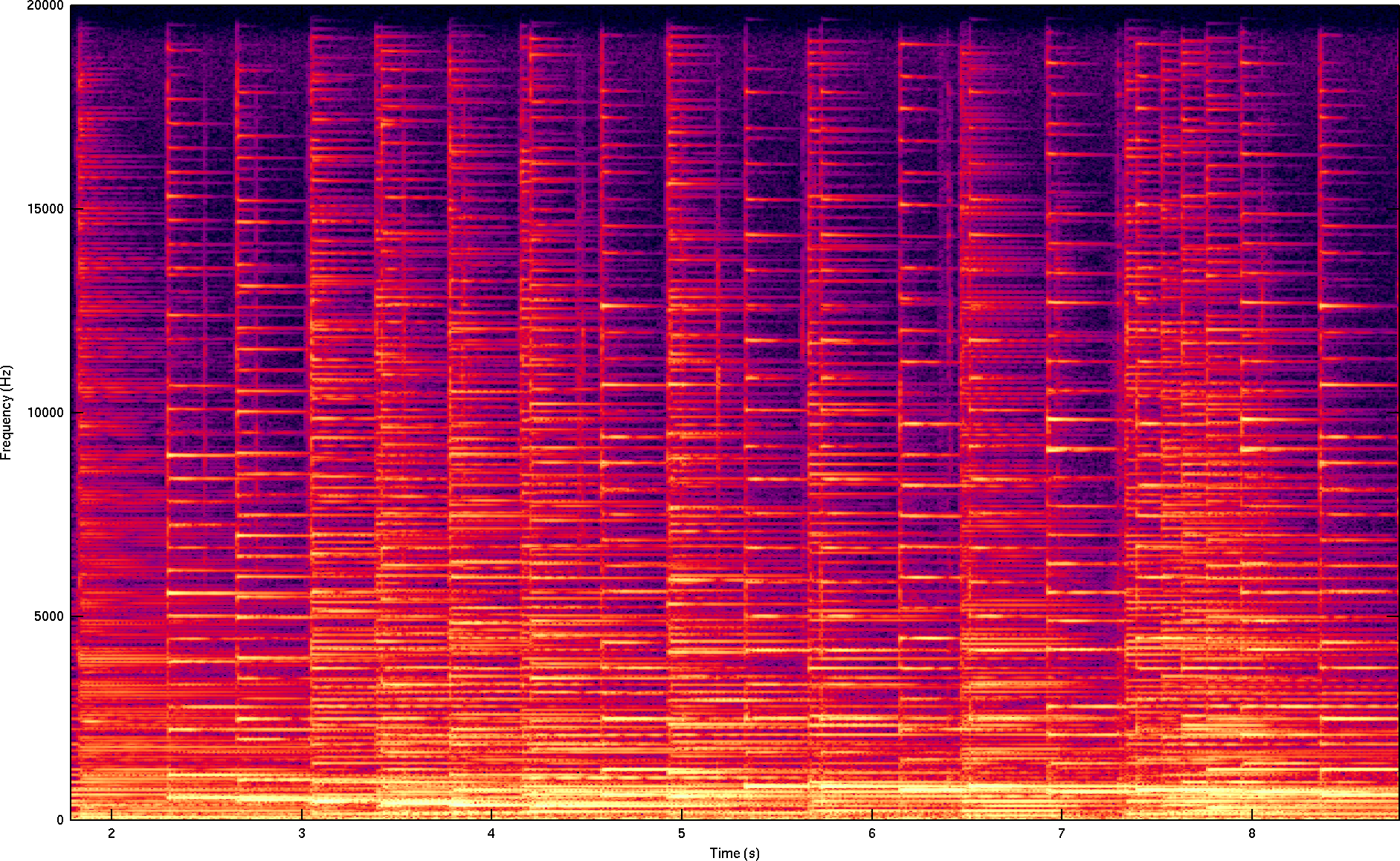
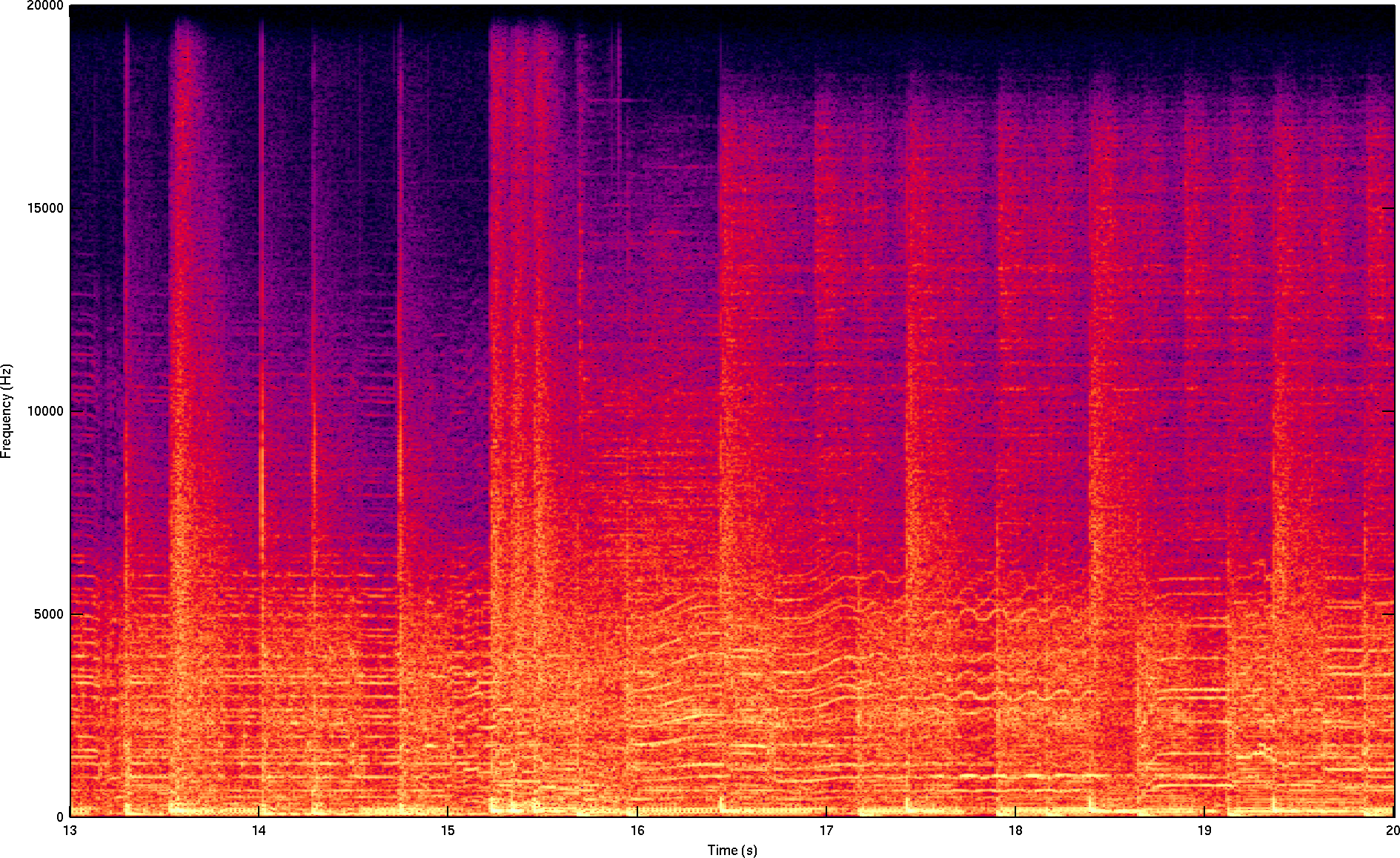
The harpsichord is a good example of both concerns. It is both strongly tonal, and produces exceptionally strong harmonics into the upper limits of the audible spectrum. A harpsichord was, in fact, the sample on which Opus 1.0 performed worst in the 2011 64 kb/s HydrogenAudio listening test.
The first step toward improving tonal samples is identifying them, so libopus 1.1 adds a tonal estimator to calculate the realtime tonality of the audio. The idea is simple; we compute a short time FFT, calculate the phase of each frequency bin, and compare this to previous FFTs. The phase of a continuous tone varies linearly (it is not constant unless the tone is perfectly aligned with a bin, which is unlikely), so our continuity estimate is:
![<i>C</i>(<i>t,f</i>) = [<i>φ</i>(<i>t</i>-1,<i>f</i>) -
2<i>φ</i>(<i>t</i>,<i>f</i>) +
<i>φ</i>(<i>t</i>+1,<i>f</i>)] mod 2*π](tonality_phase1.png)
The closer C(t,f) is to zero, the more likely we are to have a tone at that frequency. When we find tones in many regions of the spectrum, we consider the frame to be tonal and increase its bitrate.
|
Bitrate adjustment based on tonality estimation
|
||||||||||||||
|
total bitrate
|
|||||||||||||
| download these samples: | [ | harpsichord | | | ...without tonal estimation | | | ...with tonal estimation | ] |
| [ | steam engine | | | ...without tonal estimation | | | ...with tonal estimation | ] | |
| [ | 80s Rock | | | ...without tonal estimation | | | ...with tonal estimation | ] |
Going into detailed analysis of 1.1's speed improvements could fill an entire demo, but it's worth mentioning it's not just a little bit faster. All processors see some decoding speed boost in 1.1, and we've also landed a number of NEON optimizations for ARM that improve all encoding and decoding modes. For example, 96kbit/sec stereo decode on ARM processors is currently 68% faster (40% less time) and encode is 29% faster (22% less time).
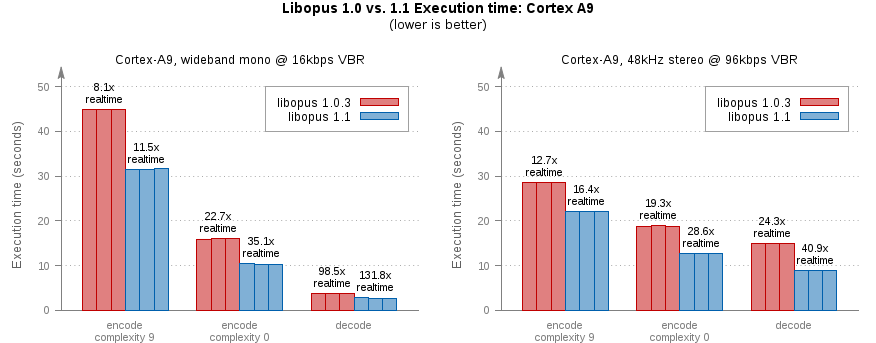
Above: Execution time of libopus 1.0.3 vs. 1.1 fixed-point builds on an ARM OMAP4460 core (Cortex A9) running at 1.2GHz. The test input is the standard comp48s.wav sample looped four times. Bars are shown for three runs of each test case and labeled with the average realtime performance across the three runs.
The graph at left shows execution time for encoding a mono wideband 16kbps VBR stream at complexity 9 (the highest quality setting) and complexity 0 (the fastest). The last bar shows execution time for decoding the stream produced at complexity 9. The graph at right shows encoding and decoding times for a fullband (48kHz) stereo encode at 96kbps.
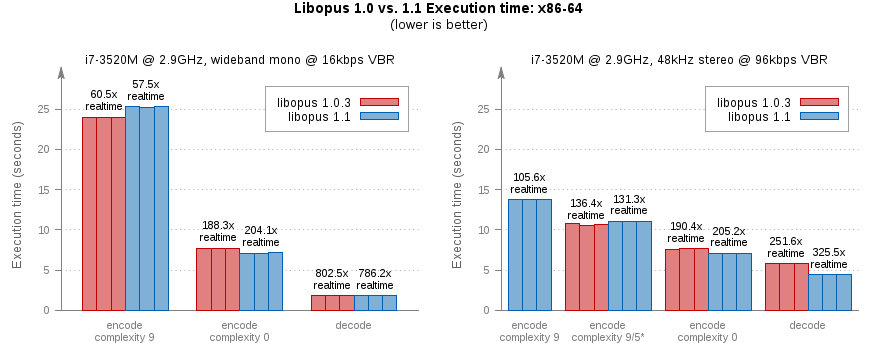
Above: Execution time of libopus 1.0.3 vs. 1.1 fixed-point builds on a core i7-3520M running at 2.9GHz. The test input is the standard comp48s.wav sample looped sixteen times. Bars are shown for three runs of each test case and labeled with the average realtime performance across the three runs.
The graph at left shows execution time for encoding a mono wideband 16kbps VBR stream at complexity 9 (the highest quality setting) and complexity 0 (the fastest). The last bar shows execution time for decoding the stream produced at complexity 9. The graph at right shows encoding and decoding times for a fullband 48kHz stereo encode at 96kbps. Speed improvements in libopus 1.1 are mostly limited to fullband decode on x86[-64].
There's one odd caveat highlighted in the right-hand graph; libopus 1.1 adds additional analysis to fullband encoding; in terms of both speed and quality, complexity level 9 in 1.0.3 is roughly the equivalent of complexity level 5 in libopus 1.1.
The 1.1 release contains several other improvements. They're less bloggogenic, but there's no reason to neglect mentioning them entirely.
Mid/side stereo encoding is an easy way to improve compression in the most common case, when the left and right (or any two) channels are similar. When the left and right channels are completely different or only slightly correlated, then mid-side coding provides little improvement. When the left and right channels are highly correlated — nearly identical or actually identical — then the efficiency increase approaches a factor of two. Obviously, quantifying exactly how much savings we can extract from coupling is useful to informing VBR rate allocation.
The relation turns out to be simple. For a left-right correlation z, we have:
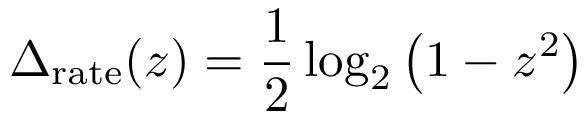
Delta represents the optimal change in quantization resolution in bits/sample. We cap the actual allocation decrease to a maximum that depends to the number of frequency bins actually coded in mid/side stereo; see /* Stereo Savings */ in celt/celt_encoder.c for the details.
Opus does not explicitly transmit quantizers for each band, nor does it have an equivalent of MP3's scalefactors or Vorbis's floor curve. Instead, Opus transmits the energy of each band, then determines quantization for each band using a fixed table-driven algorithm. The number of bits saved by not encoding scalefactors or a floor almost always outweighs the inflexibility of the fixed allocation by a substantial margin.
That said, there are cases where the fixed allocation is suboptimal, and the Opus bitstream allows the encoder to make modifications to the fixed allocation, dynamically granting more bits to specific bands that need it. This is done via two explicitly signaled mechanisms, Dynamic Allocation and Spectral Tilt.
Dynamic allocation is a means of granting more bits to a single specific band. For example, transient handling switches to a smaller MDCT that improves time resolution but increases spectral leakage. The leakage may be audible when the transient coincides with strong tones. Similarly, exceptionally high-energy bands can leak noise and other artifacts into surrounding quiet bands where they may be audible. In both cases, dynamic allocation reduces stray spectral leakage by increasing the precision of the coded representation.
Spectral tilt performs a similar function by shifting relative bit allocations toward the lower or higher frequencies across the entire spectrum. This is primarily a means of handling samples with more or stronger harmonics than are typical of natural audio; strong HF harmonics require greater relative precision in high frequencies.
Libopus 1.1 enables both techniques for surround encoding, and improves use of both mechanisms for mono and stereo samples.
The 1.1 encoder now uses a built-in DC rejection filter (3Hz cutoff) for all modes. The effect of the filter itself is inaudible, but it prevents DC energy from polluting the masking and energy analysis of the lowest frequency bands.
Previous Opus encoders offered only CBR and ABR with a short time window. As of 1.1, the encoder implements true unconstrained VBR. When using VBR, the bitrate option selects a VBR mode that hits the approximate requested bitrate for most samples (exactly the same as in Vorbis). The encoder has the freedom to use more or fewer bits at any time as it sees fit in order to maintain consistent quality.
1.1 also adds temporal VBR, an accidental discovery from a bug in an earlier pre-release. Temporal VBR is new heuristic that adds bits to loud frames and steals them from quiet frames. This runs counter to classic psychoacoustics; critical band energies matter, not the broadband frame energy. In addition, TVBR does not appear to be exploiting temporal postecho effects.
Nevertheless, listening tests show a substantial advantage on a number of samples. I'll be the first to admit we haven't completely determined why, but my best theory is that strong, early reverberant reflections are better coded by the temporary allocation boost, stabilizing the stereo image after transients especially at low bitrates.
