
The latest version of the CELT reference library implementation can always be downloaded from http://celt-codec.org/downloads.
By way of general feature summary:
While primarily targeted at packet oriented networks, CELT includes a number of design features that increase robustness to bit errors, also making it suitable for non-IP wireless applications.
This is similar to the 'cell phone collisions' many cell phone users experience when the lower but still significant (~100ms) delays over a cell phone link result in both speakers repeatedly beginning to speak at the same time, both stopping to let the other speaker continue, and then both beginning to speak again resulting in another collision. Lather, rinse, repeat.
Simplified CELT block diagram
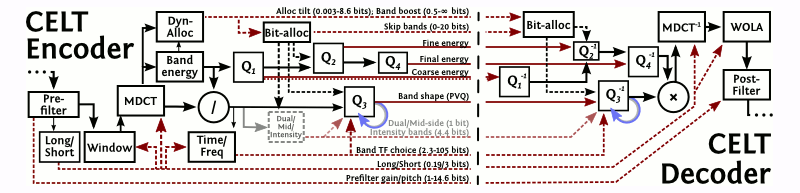
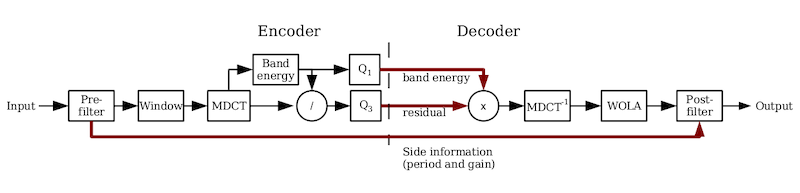
"CELT" stands for "Constrained Energy Lapped Transform" an accurate and remarkably unforced acronym. It is exactly that: A lapped transform codec with a psychoacoustic design philosophy based on band-energy preservation.
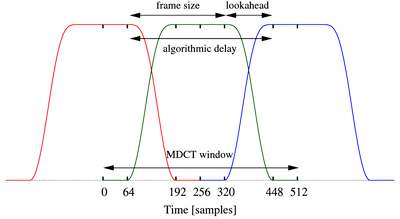 CELT is a lapped transform-domain codec like Vorbis and AAC,
however it uses quite short windows with low overlap to achieve
low latency.
CELT is a lapped transform-domain codec like Vorbis and AAC,
however it uses quite short windows with low overlap to achieve
low latency.
Despite the small windows and short overlap, transient pre-echo suppression occasionally demands yet shorter windows. In this case, the frame is split and smaller MDCTs are done on each piece. The results are then interleaved and coded as normal.
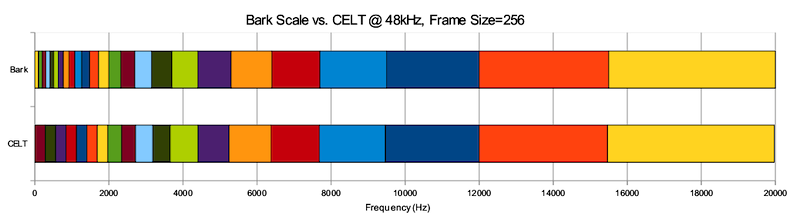
The spectral lines produced by each transform are grouped and coded by critical band. This both holds coding noise within critical bands and also provides approximately correct band energy resolution.
The single most important new discovery in Vorbis was that preserving narrowband energy produces far superior results to earlier techniques that attempted to globally minimize quantization noise. This was a relatively late discovery in the Vorbis project, and although it was easy enough to add energy preservation to the Vorbis encoder ('Noise Normalization'), Vorbis did not incorporate energy preservation as an inherent design concept.
CELT's design assumes unity narrowband energy gain throughout. The absolute energy of each band is explicitly coded, and every entropy-backend codeword also encodes unity energy. Critical band spectral energy and the coarse shape of the spectral envelope is thus preserved no matter what.
In addition to increasing time resolution via frame splitting, CELT can also further adjust time/frequency resolution by performing Hadamard transforms in one band. A forward Hadamard transform over several blocks increases frequency resolution and an inverse transform in one block increases time resolution (though with more temporal leakage than via frame splitting). TF adjustment is signaled per band and used to further bias a frame toward more accurately encoding tonal or transient content.
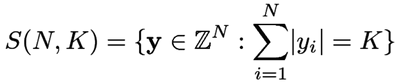
CELT encodes energy in each band explicitly. The spectral residue of each band is quantized as a whole band using a fixed number of spectral energy 'pulses' (K). These pulses are amplitude (not energy) quanta that total an amplitude of 1.; each pulse represents an amplitude of 1./K. Each codeword is thus an N-dimensional vector of integer magnitudes that sum to K. The codeword space is obviously countable, representing points on the surface of an N-1 orthoplex (the dual of a hypercube; a 3 dimensional orthoplex is an octahedron).
The astute reader will notice that in the above explanation, each codeword represents a fixed summed amplitude, not a fixed energy. The orthoplex is warped such that the energy of each vector is normalized to an energy of 1., inflating the vectors to points on an N-1 sphere. The direction of each vector is not altered, resulting in higher resolution at the 'poles'. In this form, the codewords also turn out to have approximately flat probability, eliminating the need for entropy encoding of residual data.
The specific implementation of this coding technique used by CELT is known as Pyramid Vector Quantization (Fischer, 1986) The design neatly sidesteps any need for Vorbis-like codebooks in residue coding.
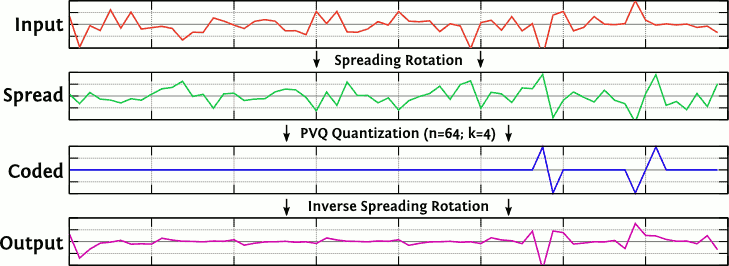
If too much diffuse energy in a band collapses into just a few pulses due to very low bitrate coding, this causes the classic swirling/metallic artifacts typical of transform codecs. These artifacts are mostly associated with mp3, which has the least ability to mitigate the problem.
Following the equation above, spectral collapse happens primarily when K is small, causing an audibly sparse spectrum. Spreading essentially jitters pulses around as a kind of spectral dither; if and when low-bitrate encoding collapses a noisy spectrum into just a few pulses after the forward spreading filter, the inverse filter in the decoder 'unjitters' the collapsed energy, spreading it back out across the narrowband spectrum.
It might not be obvious from the description above, but spreading is purely a forward/inverse filtering operation; there is no additional side information transmitted. The only additional signaling is whether folding is enabled or disabled.
This has a similar effect to Spectral Band Replication (SBR), except that we don't replicate bands, we just reuse residue codewords from lower bands, reconstituted in the context of the encoded energy of the higher band. Much simpler in concept and execution than SBR, a lucky break of the PVQ design.
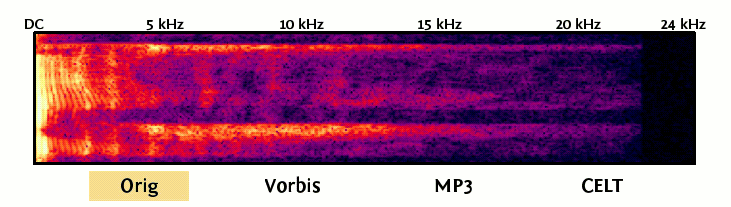
Left: an illustration of constrained energy, pulse spreading, and band folding in action. The spectrogram shows the original mono sample, MP3 at 32kbps, Vorbis at 32kbps and CELT at 32kbps. Vorbis also preserves band energy but does not have the additional spreading and folding mechanisms.
Click on the label to show the spectrogram for each codec.
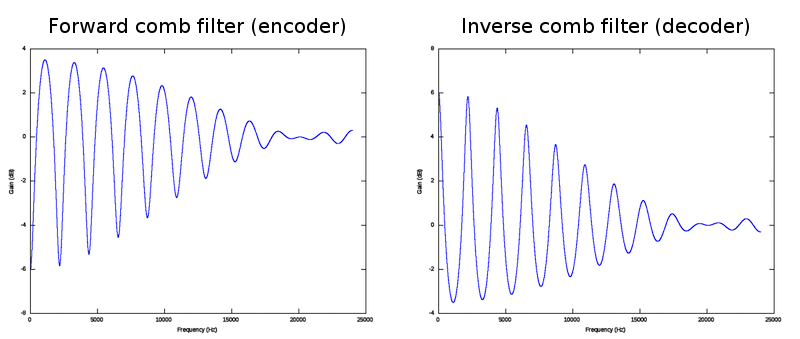
Due to the relatively poor frequency resolution resulting from CELT's very short windows, encoding strongly tonal content is challenging in ways atypical of a transform codec. Strongly tonal content requires additional techniques over straight transform/quantize for efficient coding.
As part of the CELT work going on within the IETF codec working group, Raymond Chen of Broadcom submitted a technique to weight tonal content for more efficient encoding using pitch prediction and a matched comb filter. In the encoder, the comb filter is used to weight the input signal toward the tonal content. In the decoder, the inverse filter reverses the weighting.
This technique has a few clever advantages. It wraps the preexisting CELT encoder/decoder and so the additional complexity is compartmentalized. In addition, the comb filter weights the entire harmonic structure rooted in the fundamental, not just the fundamental frequency itself.
The primary disadvantage of the technique is that it requires better than typical pitch detection. In speech codecs like Speex, pitch halving or doubling affects the efficiency of coding prediction but does not have serious consequences for encoded quality. In CELT, however, this would potentially generate phantom harmonics or drop the even harmonics of the fundamental, both obviously audible problems. As such, CELT requires (and of this writing has) a more reliable pitch predictor than typical.
This technique also currently only applies to a single fundamental. At present, Vorbis still eats CELT's lunch on strongly tonal polyphonic samples.
Recently, CELT is also able to signal that a band be filled with pseudorandom noise. Bands of pure noise (without substantial features in either frequency or time) is a more common occurrence in real-world audio than most people realize.
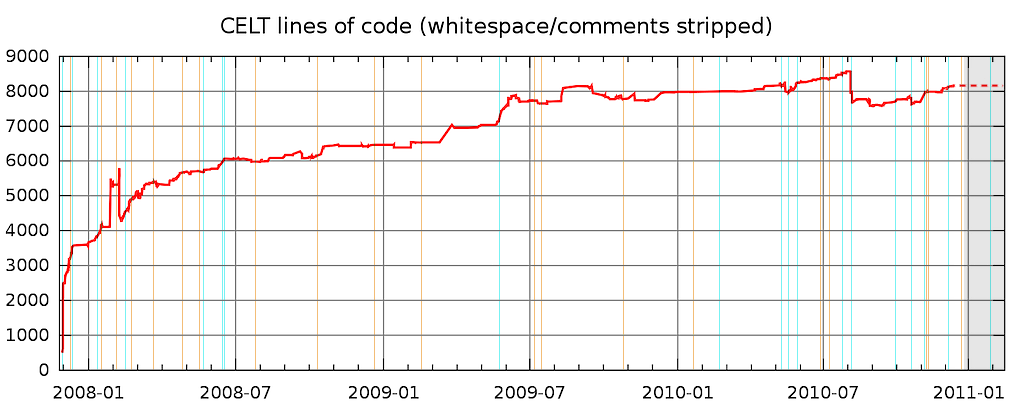
The first very early next-generation audio codec work to develop a successor to Vorbis began at Xiph in 2005. In 2007 I began more directed research on a new codec (Ghost) along with Jean-Marc Valin of Xiph's Speex project. He felt strongly that low-delay was an important feature in a new codec. At that time, we didn't reconcile the low-delay requirements with the filterbank topology I wanted to use in Ghost.
Shortly after, I decided that improving the Theora encoder was a much more pressing concern than next-gen audio development and turned my attention to the Thusnelda encoder. Jean-Marc, however, was free to continue working on the low-delay codec (CELT) that was born out of those 2007 meetings. CELT is currently nearing completion.
In the interest of documenting several dead-ends...

Early CELT used a pitch prediction/warping scheme to try to improve tonal coding that was completely different from the current comb filter approach. It was complex, expensive, and of marginal effectiveness. It was finally removed from the code November 9th, 2009.
The original technique is described in detail in the original CELT paper. To summarize, the old pitch prediction searched backwards in time through previously seen data, using cross-correlation to search for a candidate match. The idea behind this technique was that the correlation search would find both the period of the fundamental as well as a preceding window that predicted the spectrum of the current window well. Although the short window of CELT prevents resolving harmonics clearly, the theory was that finding a preceding match would also have a similar harmonic spread and thus also provide a good predictor for the unresolvable harmonics in the current frame as well.
Unfortunately, results were mixed; although the predictor was better than nothing in many cases, its utility could best be described as marginal, and it was decided it was certainly not worth the computational cost.
Short blocks in CELT are coded as if they're a normal frame with spectral values from each short MDCT interleaved to produce a full frame's worth of spectral data; the data is encoded as if it were the product of a single MDCT. Because short blocks are used only for impulsive frames, the energy levels of of the data from each MDCT may vary by quite a large amount. For a period of time, CELT was able to weight the MDCTs of individual short blocks to equalize the energies from before and after the impulse. The idea sounds obviously useful, but proved to be of dubious utility (and required signaling bits to use). MDCT weighting has been disabled for some time and was finally dropped from the code on October 18, 2010.
 Here I present a few canned CELT demos, decoded to WAV so that it
is possible to evaluate and compare without needing to build or
install myriad old versions of the CELT decoder. Feel free to
download the samples and use a comparison application (such as
Xiph.Org's squishyball
comparison/testing utility, pictured left) for casual or more
rigorous comparison.
Here I present a few canned CELT demos, decoded to WAV so that it
is possible to evaluate and compare without needing to build or
install myriad old versions of the CELT decoder. Feel free to
download the samples and use a comparison application (such as
Xiph.Org's squishyball
comparison/testing utility, pictured left) for casual or more
rigorous comparison.
The original uncompressed sample can be downloaded here. The complete set of demo samples below is directly downloadable here. These encodes are remarkably low-rate for a general purpose low-latency codec; I've done this on purpose to make the differences easy to hear.
Be aware that Firefox has a playback bug that might cause clicking during playback. It's a browser problem, not part of the samples, and it's fixed in the 4.0 beta prereleases.
Playback: [ uncompressed | 96kbps | 64kbps | 48kbps | 32kbps |
Download: [ uncompressed | 96kbps | 64kbps | 48kbps | 32kbps |
Playback: [ uncompressed | 22.5ms (64kbps) | 12.5ms (70.4kbps) | 7.5ms (84.8kbps) | 5ms (112kbps) ]
Download: [ uncompressed | 22.5ms (64kbps) | 12.5ms (70.4kbps) | 7.5ms (84.8kbps) | 5ms (112kbps) ]
As CELT's bitrate performance improved, however, it also became natural to compare it to high-latency general purpose codecs such as AAC-LC (intended for low complexity, >100ms latency), HE-AAC v1 and v2 (intended for very low bitrates, latency >200ms) and Vorbis (general purpose, latency >200ms).
The only AAC-LD encoder I could find (Quicktime Pro) offers down to 64kbps for 48kHz stereo, so it does not appear in the less-than-64kbps comparisons below.
Playback: [ uncompressed | Vorbis | AAC-LC | AAC-LD | HE-AAC v1 | HE-AAC v2 | CELT ]
Download: [ uncompressed | Vorbis | AAC-LC | AAC-LD | HE-AAC v1 | HE-AAC v2 | CELT ]
Playback: [ uncompressed | Vorbis | AAC-LC | HE-AAC v1 | HE-AAC v2 | CELT ]
Download: [ uncompressed | Vorbis | AAC-LC | HE-AAC v1 | HE-AAC v2 | CELT ]
Working with Skype and others within the IETF, Xiph drove the creation of a working group to produce a royalty-free codec for general-purpose internet usage, including telepresence. Several codecs have been submitted as working material, including CELT. A combination of CELT and Skype's SILK codec has been adopted as the primary development target of the working group.
Skype's SILK codec is a state of the art codec for low to moderate bitrate speech (yes, it's better than Speex). It isn't great for music, and it doesn't do very high quality, but it's fantastic for an important set of applications. The combination with CELT gives good performance from 6kbit/sec to transparency.