
Ever since version 1.1, Opus has been able to automatically detect whether its input is speech or music, and choose the optimal encoding mode accordingly. The original speech/music detector was based on a simple (non-recurrent) neural network, followed by an HMM-based layer to combine the neural network results over time. While it worked reasonably well most of the time, it was still far from perfect. Thanks to deep learning — and specifically recurrent neural networks — we can now do better.
Opus 1.3 includes a brand new speech/music detector. It is based on a relatively new type of recurrent neuron: the Gated Recurrent Unit (GRU). Unlike simple feedforward units, the GRU has a memory. It not only learns how to use its input and memory at each time, but it can also learn how and when to update its memory. That makes it able to remember information for a long period of time but also discard some of that information when appropriate.
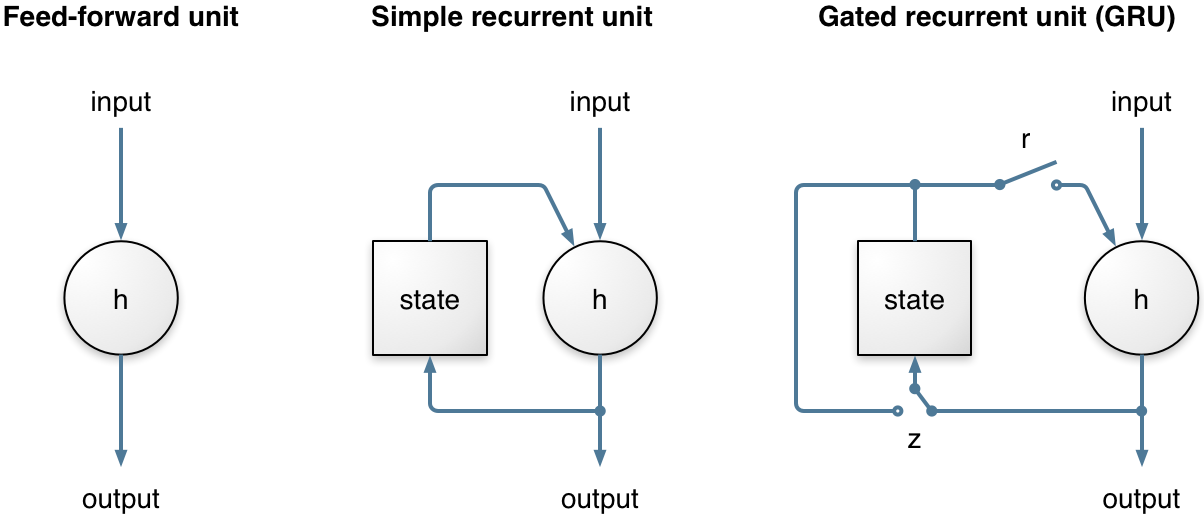
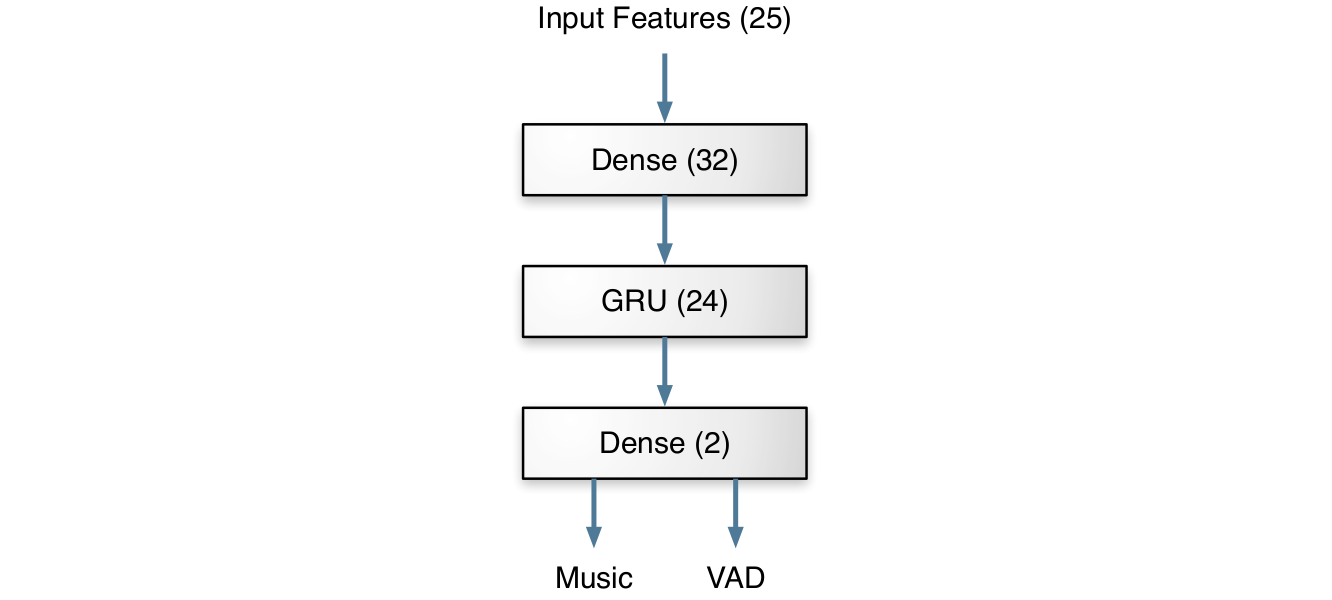
Because distinguishing between speech and music is much easier than, say, speech recognition, the network can be pretty small. Instead of thousands of neurons and millions of weights running on a GPU, the Opus detector has just 4986 weights (that fit in less than 5 kB) and takes about 0.02% CPU to run in real-time. The figure below shows how the layers of the network are arranged. Although it doesn't look very deep, it's actually quite deep over time thanks to the GRU.
Revisiting the original 1.1 demo example, let's see what these improvements actually look like in practice.
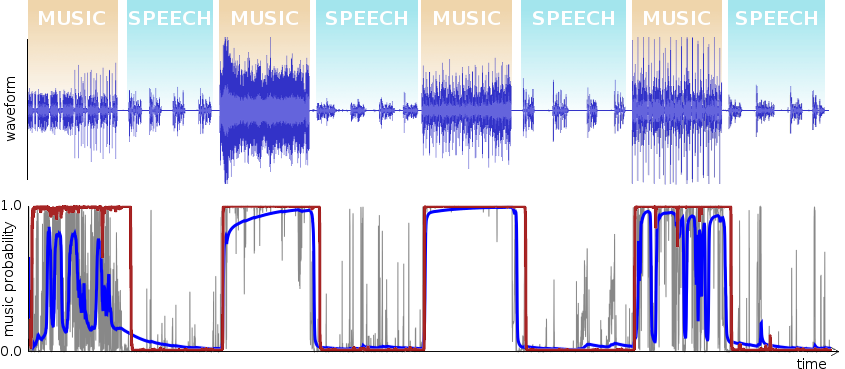
A neural network only gives us a probability that any given frame is speech or music. From there, we have to make an actual decision based not only on that probability (and how it evolves over time), but also based on the bitrate and whether/when the audio is active or inactive (silent/noise). That decision logic has also been improved in 1.3. The encoder now minimizes a badness metric, which includes penalties for using the wrong mode, but also for switching in the middle of speech or music. When look-ahead is available, the decision logic is able to have the encoder switch mode during a silence period before the transition between speech and music.
Back in 2010-2012, when we were combining SILK and CELT into Opus, there was a lot of work to do. We were already amazed we could code high-quality fullband speech at 32 kb/s that we didn't really attempt to go beyond that. Combined with the fact that Opus has a total of 64 different operating modes (combinations of SILK/CELT/hybrid, bandwidths, frame sizes, mono/stereo), it's easy to see why not everything was fully optimized when the 1.0 encoder came out. For 1.3, there's been some more tuning for low-bitrate speech.
First, it turns out that the Opus encoder was never actually tuned for stereo speech below 40 kb/s. By just changing how the encoder divides the total bitrate between the SILK and CELT parts, we were able to significantly improve stereo speech quality, especially in the 24-32 kb/s range. On the SILK side, the encoder is now giving more bits to the side (left-right difference) channel, lowering the bitrate at which stereo information starts being coded for speech.
Deciding what bandwidth to use depending on the bitrate has always been tricky since it eventually becomes a matter of personal preference. The original tuning was mostly based on my personal preference, plus a "safety margin" erring on the side of lower coding noise and narrower bandwidth. It appears that most people do not share my preferences and tend to prefer wider bandwidths, even if it means more coding noise. That is why we have been changing the decision threshold over time. For example, the Opus 1.0 encoder would only use wideband if the bitrate was at least 14 kb/s. That threshold was lowered to 11 kb/s back in the 1.2 release. Now, thanks to an (unpublished) experiment by folks at Google, we know that most people actually prefer wideband to narrowband even at 9 kb/s. That's why 1.3 now switches from narrowband to wideband at 9 kb/s. You might ask "where's mediumband?" (12 kHz sampling). Well, given these changes, it's no longer useful and will not be used except for a few specific situations (e.g. when the user explicitly asks for it). Of course, since it is part of the Opus specification, it will still remain in the decoder forever (the cost is very small anyway).
Because of how SILK is designed, there's a limit to how low a bitrate it can produce. No matter what the target bitrate is, the actual average bitrate will never go below a certain value. For previous releases (1.0-1.2), that minimum was around 6 kb/s for narrowband and 9 kb/s for wideband. Thanks to some reworking of the SILK rate control logic, the Opus 1.3 encoder can now encode speech at bitrates down to 5 kb/s for narrowband and 6 kb/s for wideband. Note that this does not by itself improve quality. It only makes some lower rates available.
Here are some samples showing how Opus' speech quality has evolved since 1.0 for different bitrates.
Select codec/version
Select bitrate
Select where to start playing when selecting a new sample
Player will continue when changing sample.
Comparing stereo speech quality of versions 1.0, 1.1, 1.2, and 1.3 at bitrates between 9 and 48 kb/s. This demo will work best with a browser that supports Ogg/Opus in HTML5 (Firefox, Chrome and Opera do), but if Opus support is missing the file will be played as FLAC, WAV, or high bitrate MP3.
Opus 1.3 adds support for immersive audio using ambisonics that surrounds the listener in a full-sphere sound field. This is done through two new (soon to be RFC 8486) Ogg mapping families for Opus ambisonics. Unlike other multi-channel surround formats, ambisonics is independent of speaker layout. This allows for flexible speaker configurations and scalable audio to efficiently transmit 3D audio soundtracks. Ambisonics is particularly effective when combined with 360 videos to envelop the listener’s senses. The spatial resolution of an ambisonics sound field is determined by its order. Generally speaking, increasing the order of ambisonics improves spatial resolution, but requires a higher bitrate, since the number of channels is given by (ambisonics order + 1)^2. These channels are ordered according to the Ambisonic Channel Number (ACN) format. The maximum ambisonics order supported by Opus is 14; in practice, up to the 3rd order is commonly used. In addition to ambisonics, 2 channels (stereo) can be added for non-diegetic (head-locked) audio.

Opus 1.3 includes two channel mappings for ambisonics encoding: channel mapping families 2 and 3. For first order ambisonics, it is generally best to use channel mapping 2, which codes each ambisonic channel independently. For all higher-order ambisonics, channel mapping 3 provides a more efficient representation by first transforming the ambisonics signals with a designated mixing matrix before encoding. This 1.3 release provides matrices for first, second, and third order.
Here are some ambisonics samples that have been encoded with Opus. For the purpose of this demo, they have been down-mixed to stereo for playback with regular headphones.
Select codec/version
Select bitrate
Select where to start playing when selecting a new sample
Player will continue when changing sample.
Evaluating the quality of ambisonics encoding for first and third order. This demo will work best with a browser that supports Ogg/Opus in HTML5 (Firefox, Chrome and Opera do), but if Opus support is missing the file will be played as FLAC, WAV, or high bitrate MP3.
Here are briefly some of the more minor changes in this release.
One of the fundamental assumptions in CELT is that any given band tends to have a fixed perceptual contribution, no matter how loud or quiet it is. While that assumption holds remarkably well across a wide variety of signals, it does get broken occasionally, especially on sparse tonal signals. By this we mean signals that have are made up of only a handful of tones. These are often synthetic (e.g. a sine wave generator), but can also happen in real life (e.g. glockenspiel). For these signals, we have bands with essentially no energy, at which point it's best to disregard the band and only pay attention to the few bands that hold the tones. This is what Opus 1.3 does now for these signals, slightly improving quality (though probably not something you would easily notice on most files).
The Opus 1.2 demo discussed some updates being made in the Opus standard. Back then, the changes were disabled by default in the code because they were not yet approved by the IETF. Since then, they have been published as RFC 8251 and Opus 1.3 now enabled the changes by default. They can be disabled by configuring with --disable-rfc8251, but there is no reason to do so, since the changes do not affect interoperability in any way.
Opus has been extensively tested and fuzzed for several years now. As of version 1.3, Opus is now attempting to defend itself from bugs outside of its scope, i.e. in the applications calling the API. While C makes it impossible to be fully shielded from the application code (e.g. it's not even possible to verify that a pointer is valid), there are still some checks we can make. One of the ways a bug in the application can cause Opus to crash is by corrupting the encoder or decoder state and then calling Opus with the corrupted state.
Another security improvement in 1.3 comes from assertions. Like many other packages, Opus used to only enable assertions for "debug" builds. In 1.3, the assertions that meet the following criteria are now enabled by default:
The result is again that should an attacker manage to cause (directly or indirectly) a corruption in Opus, the application will be more likely to just crash rather than be taken over.
—Jean-Marc Valin (jmvalin@jmvalin.ca) October 18, 2018{kind=link}