

This demo presents the LPCNet architecture that combines signal processing and deep learning to improve the efficiency of neural speech synthesis. Neural speech synthesis models like WaveNet have recently demonstrated impressive speech synthesis quality. Unfortunately, their computational complexity has made them hard to use in real-time, especially on phones. As was the case in the RNNoise project, one solution is to use a combination of deep learning and digital signal processing (DSP) techniques. This demo explains the motivations for LPCNet, shows what it can achieve, and explores its possible applications.
Back in the 70s, some people started investigating how to model speech. They realized they could approximate vowels as a a series of regularly-spaced (glottal) impulses going through a relatively simple filter that represents the vocal tract. Similarly, unvoiced sounds can be approximated by white noise going through a filter.
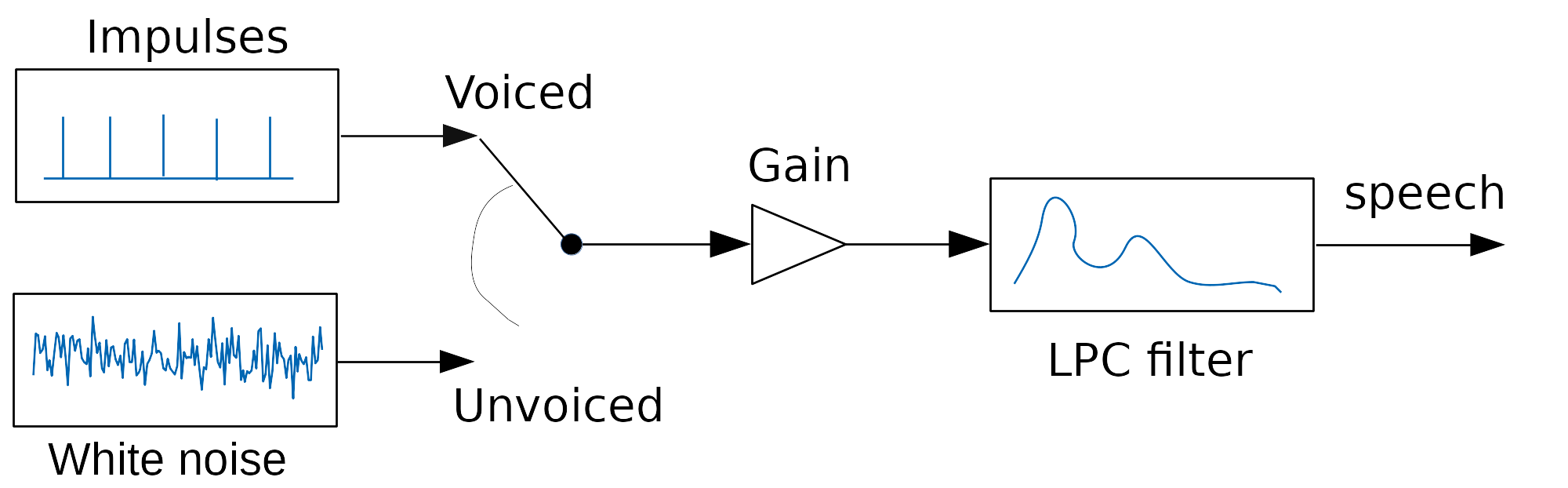
With just that simple model, it's possible to either synthesize intelligible speech, or compress speech at very low bitrate. This is what such a simple model sounds like (LPC10 vocoder at 2.4 kb/s):
So intelligible speech, but by no means good quality. With a lot of effort, it's possible to create slightly more realistic models, leading to codecs like MELP and codec2. This is what codec2 sounds like on the same sample:
Codec2 is quite good considering it only uses 2.4 kb/s (or less), but it's still far from what would be considered high quality speech.
Despite small improvements, there was no major breakthrough in speech synthesis — until the deep learning revolution of the past few years. In 2016, the DeepMind folks presented WaveNet (demo, paper), a deep learning model that predicts speech one sample at a time, based on both the previous samples and some set of acoustic parameters (e.g. a spectrum). One key aspect to understanding WaveNet and similar architectures is that the network does not directly output sample values. Rather, the output is a probability distribution for the next sample value. From that distribution, there is a sampling step that generates a random value using the distribution and the result becomes the next sample value. That new sample is then fed back to the network so that the following values are consistent with all previous decisions. It's normal to wonder why we don't just pick the most likely value for the next sample, or why the network doesn't directly output the most likely value. The reason is that speech is inherently random. The best example is sounds like "s", which are essentially gaussian-distributed random noise. If we were to pick the most probable value for each sample, we would be generating all zeros, since each sample is just as likely to have a positive value as a negative value. In fact, even though vowels have less randomness than unvoiced sounds, all phonemes have some randomness, which is why we need to have this sampling operation.
WaveNet can synthesize speech with much higher quality than other vocoders, but it has one important drawback: complexity. Synthesizing speech requires tens of billions of floating-point operations per second (GFLOPS). This is too high for running on a CPU, but modern GPUs are able to achieve performance in the TFLOPS range, so no problem, right? Well, not exactly. GPUs are really good at executing lots of operations in parallel, but they're not very efficient on WaveNet for two reasons:
The WaveRNN architecture (by the authors of WaveNet) comes in to solve problem 1) above. Rather than using a stack of convolutions, it uses a recurrent neural network (RNN) that can be computed in fewer steps. The use of an RNN with sparse matrices also reduces complexity, so that we can consider implementing it on a CPU. That being said, its complexity is still in the order of ~10 GFLOPS, which is about two orders of magnitude more than typical speech processing algorithms (e.g. codecs).
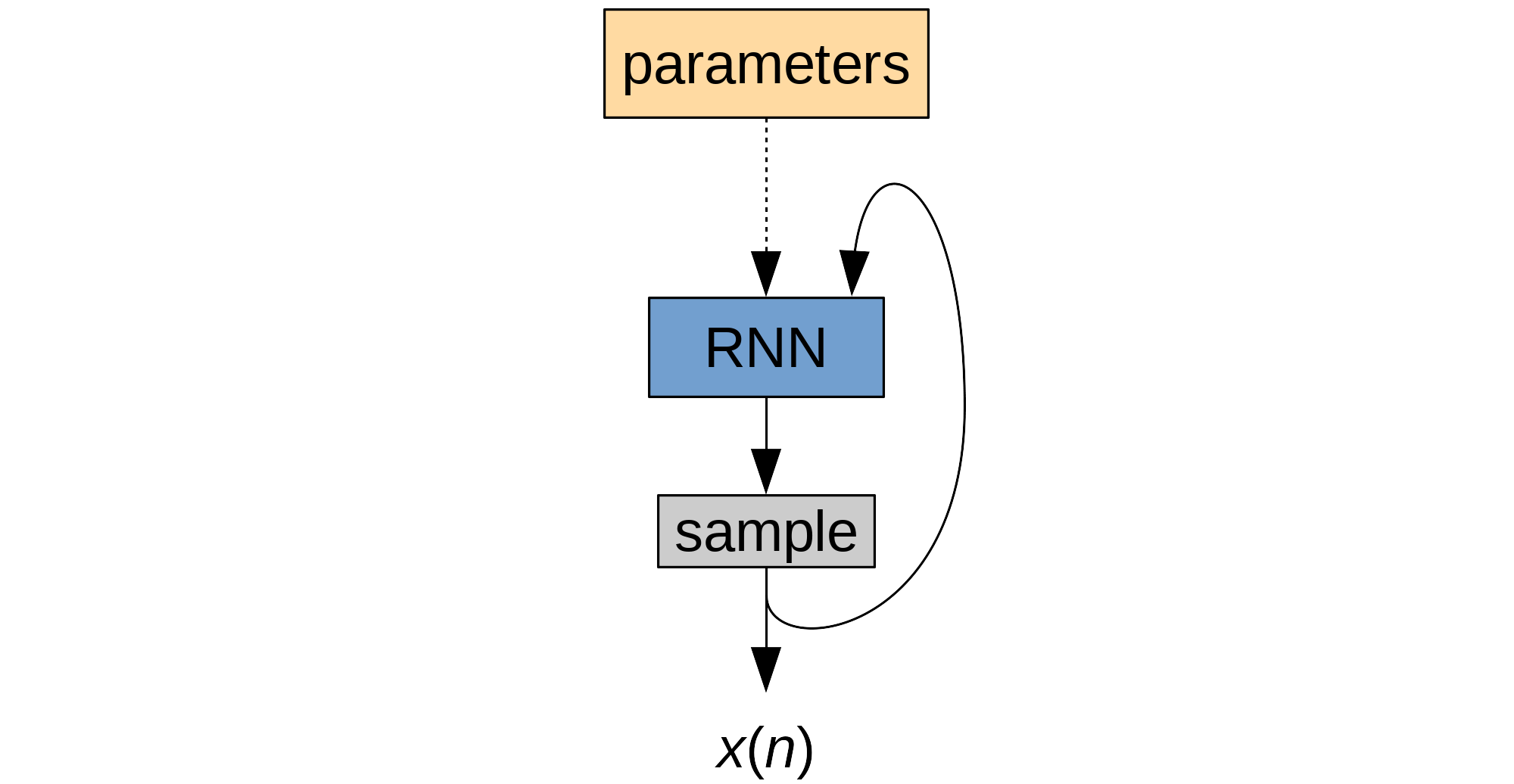
One of the reasons "pure neuron" approaches are expensive is that the neurons have to do all the work. They not only have to generate plausible glottal pulses, but they also have to simulate the filtering in the vocal tract. That filtering is easy to do with 70s digital signal processing (DSP), but it's actually hard to do for a neural network. That's because the DSP operations needed for the filtering don't map very well to neural networks. First, computing prediction coefficients from a spectrum essentially requires solving a system of linear equations. There are efficient DSP algorithms to do that (e.g. Levinson-Durbin), but you can't really implement an equivalent with just a few layers of neurons. Even implementing the filtering itself — which is a linear operation — doesn't map well with the WaveNet or WaveRNN architectures. That's because the filtering involves multiplying different inputs together, whereas networks will typically compute linear combinations of inputs, with no multiplicative terms between the inputs. Of course, we could create a strange architecture that's able to learn the filtering, but at that point, why not just add some DSP blocks to directly help a more conventional neural network?
That's where LPCNet comes in. The approach can be summarized as "don't throw the DSP out with the bath water". LPCNet is a variant of WaveRNN with a few improvements, of which the most important is adding explicit LPC filtering. Instead of only giving the RNN the selected sample, we can also give it a prediction (i.e. an estimate) of the next sample it's going to pick. That prediction doesn't have to be perfect, and it won't include the random component, but it is very cheap to compute and ends up replacing a lot of neurons. We can also make the network predict the difference between the next sample and the prediction, a.k.a. the excitation. Now our network is no longer working hard on modeling the vocal tract (though it can fix any problem with the prediction).
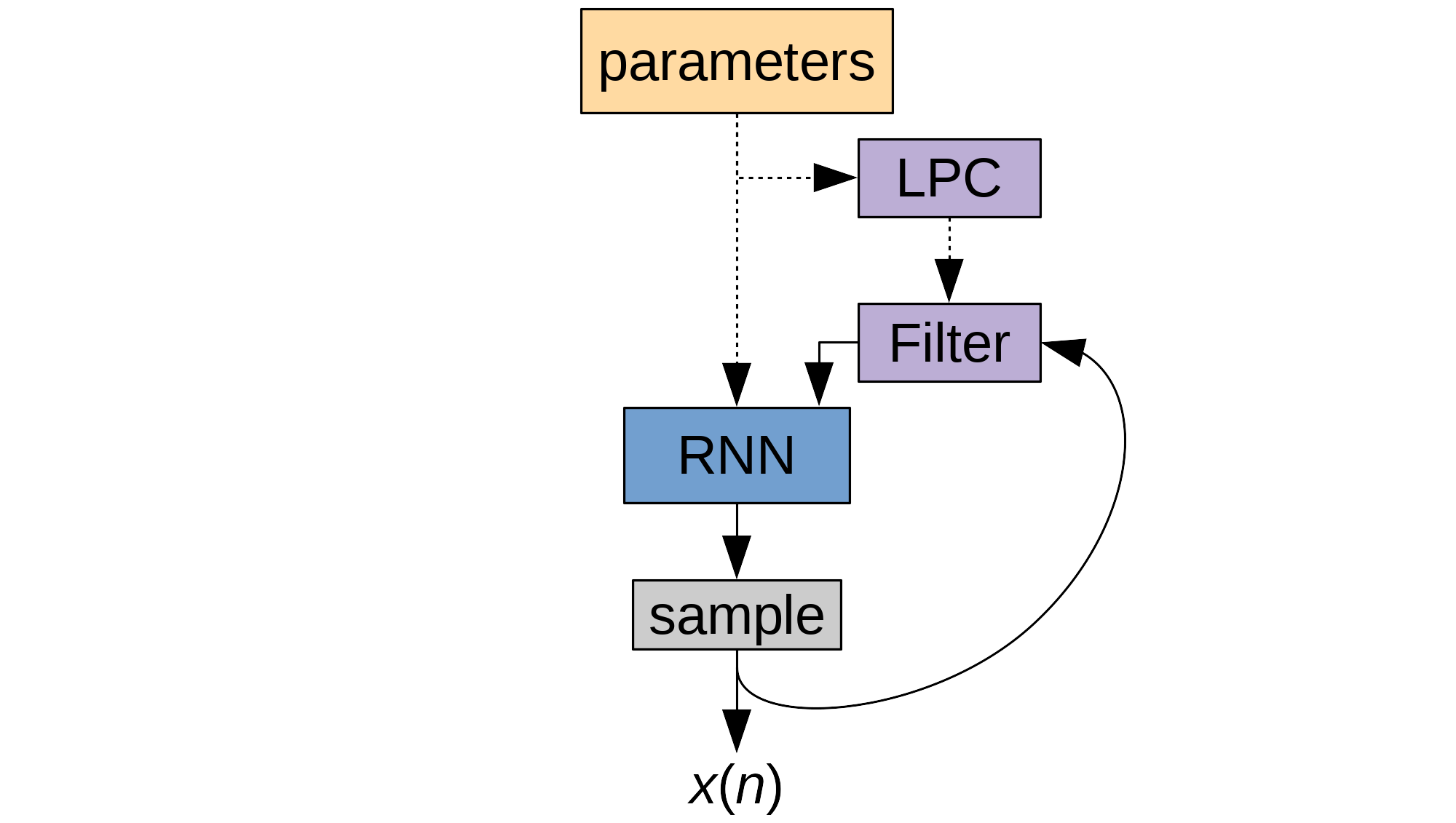
Beyond linear prediction, LPCNet also includes a few other tricks:
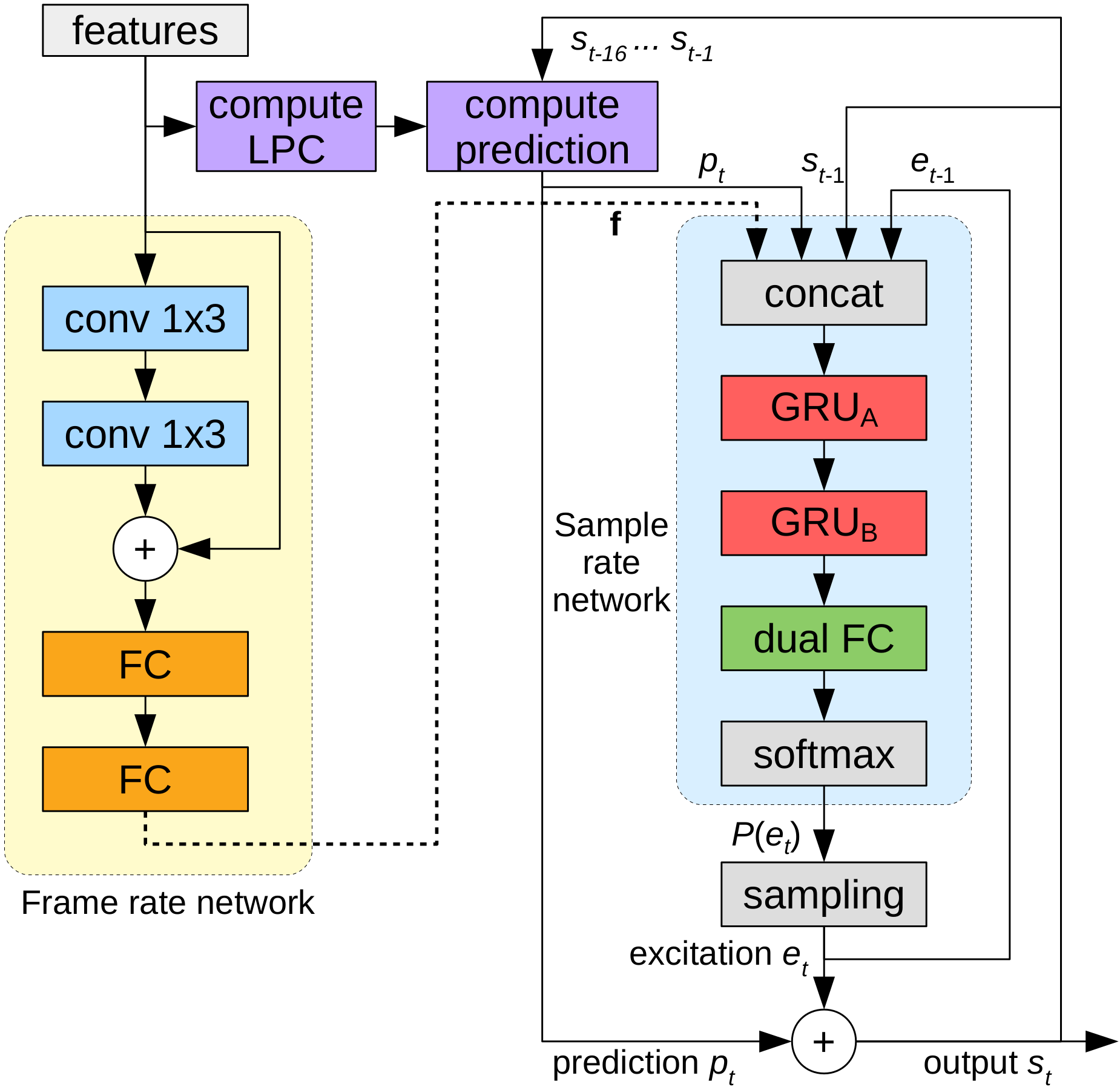
See below a more complete block diagram of LPCNet.
We ran a MUSHRA-like listening test to see how LPCNet compares to WaveRNN+, a slightly improved version of WaveRNN (without the LPC part). We had 8 utterances (2 male and 2 female speakers), each evaluated by 100 participants. The results below show that the LPC filtering in LPCNet really helps improve quality for the same complexity. Alternatively, the same quality is possible at a much lower complexity.

In the results above, the complexity of the synthesis ranges between 1.5 GFLOPS for the network of size 61, and 6 GFLOPS for the network of size 203, with the medium size network of size 122 having a complexity around 3 GFLOPS. This is easily within the range of what a single smartphone core can do. Or course, the lower the better, so we're still looking at ways to further reduce the complexity for the same quality.
Here are two of the samples that were used in the listening test above.
Select sample
Select algorithm
Select where to start playing when selecting a new sample
Player will continue when changing sample.
Comparing the speech synthesis quality of LPCNet with that of WaveRNN+. This demo will work best with a browser that supports Ogg/Opus in HTML5 (Firefox, Chrome and Opera do), but if Opus support is missing the file will be played as FLAC, WAV, or high bitrate MP3.
The LPCNet source code is available under a BSD license. To train your own model, you need:
See the README.md file for complete instructions.
Everything — and world peace! OK, maybe not quite, but there are many interesting applications once we get to the point where CPU consumption is no longer a problem. Here are just some of the possibilities.
TTS is the main reason people started looking into neural speech synthesis in the first place. They were able to effectively generate synthesis "features" (spectrum, prosody) with neural networks and other techniques, but they weren't able to actually synthesize good speech out of those features. Then, they used neural networks to do the synthesis and got good results. So LPCNet could be used within algorithms like Tacotron to build a complete, high-quality TTS system.
It's also possible to see LPCNet as a low bitrate speech codec. Last year, Google demonstrated a codec that could use codec2's bitstream and achieve good quality wideband speech even at 2.4 kb/s (samples), which in part inspired this work on LPCNet. In fact, codec2 author David Rowe has already started a (very) new project to combine LPCNet with codec2.
Read David's latest blog post for samples of his LPCNet-based codec2 implementation. Note that since codec2 has not (yet) been expanded to wideband, his samples are still narrowband (instead of the wideband samples provided above). Expect many improvements in the future.
Applications don't have to end with just TTS and compression though. With a trivial change, it's possible to turn LPCNet into a time stretching algorithm for speech. By time stretching, we mean being able to speed up or slow down a speech signal without changing the pitch. Algorithms already exist for doing that, but they often result in unnatural speech. That's where LPCNet can help. Time stretching using LPCNet is surprisingly simple: all that's needed is to tell the synthesis network to generate either more or fewer than 10 ms of speech for every 10-ms frame processed by the feature processing network.
Hear below a speech sampled slowed down by 50%.
Hear the same sample slowed down by a conventional algorithm (using SoundTouch).
The difference is especially noticeable when slowing down because then conventional pitch-based algorithms have to "make up" speech data (as opposed to discarding data when speeding up). That being said, LPCNet works quite well when speeding up too.
Another application where this work could be useful is noise suppression. Last year, we demonstrated RNNoise, which already showed pretty good results, despite its low complexity. The neural part of RNNoise works purely on the general shape of the spectrum. It can attenuate bands that have a lot of noise in them, but it doesn't know much about what speech signals are. A synthesis-based approach would be able to re-generate a plausible speech signal not only from the features, but also using the noisy signal to make sure the waveform of the denoised speech matches that of the noisy speech (minus the noise). This would also ensure that the denoiser doesn't reduce the quality of already clean speech.
If we can remove background noise from speech, we should also be able to remove speech coding artifacts. And we already know how to synthesize speech directly from the spectral features that codecs use. So by combining the two, it should be possible to significantly enhance the quality of an existing codec (Opus comes to mind here) at low bitrate, without running into the artifacts. Of course, we haven't actually tested any of this, but it wouldn't be too surprising to be able to get near-perfect narrowband speech around 6 kb/s and near-perfect wideband speech around 9 kb/s.
The last logical application of this work is for packet loss concealment. When a packet goes missing during a call, we still need to play some audio, so the receiver has to "guess" what was in that packet. In most codecs, this is done by repeating pitch patterns for voiced sounds and extending noise for unvoiced sounds. Like for time stretching, we should be able to do better. LPCNet is already trained to predict future samples from past samples and current acoustic parameters, so all we need to do is train it to predict only from past samples (and possibly past parameters). In fact, if we're already building a codec using neural synthesis, it's not hard to simply train it with random "missing" frames in its training set.
Still quite a lot. First, the code we have right now still generates samples using Keras Python code. This
would not be a problem if the network produced all the samples at once, but because of the sampling process,
speech synthesis requires running the network once for every sample we generate. Because of that, the
overhead becomes quite large, making the synthesis quite slow even though it doesn't need to be. To fix that,
what we need to do is translate the network implementation to C, just like we did for
RNNoise. Once translated to C, and before any special optimizations,
the performance should already be enough to easily run in real-time on x86 and should be close to real-time (or barely real-time)
on a recent smartphone. From there, vectorization and other optimizations should make the code easily real-time on
a smartphone and probably real-time on slower ARM devices (e.g. Raspberry Pi).
Updated: The C version of the LPCNet122 model now achieves real-time synthesis with 15-20% of a single x86 (Haswell or later) core. It also achieves real-time synthesis on a single core of an iPhone 6s. It is not (yet) real-time on a Raspberry Pi 3.
There are probably many ways of further improving the model itself and making it less complex. Some directions for future research include:
There's also a lot of work to do on applications themselves. As cool as we think LPCNet is, it doesn't actually do anything useful alone. It's more of a base technology that helps build many cool things on top of it.
If you would like to comment on this demo, you can do so on on my blog.
—Jean-Marc Valin (jmvalin@jmvalin.ca) November 20, 2018