
Since the last update from around the time of 1.1alpha2, Thusnelda has moved to the SVN trunk where work has concentrated on final features, cleanup and testing for the Theora 1.1 (Thusnelda) final. We're very close to the complete 1.1 and have already released two 1.1 release candidates. We'd optimistically scheduled final 1.1 release for last week, however we're taken some additional time to do more testing/tuning of the two-pass rate control.
At the end of July, I implemented Tim Terriberry's design for two-pass encoding within libTheora. Two-pass is used for encoding a file to a target bitrate/size while producing results that nearly identical to using variable-bitrate encoding. The first pass is used to collect metrics pertaining to the source video, while the second pass performs the actual compression. Two pass provides the advantages of variable bitrate coding while using bitrate management and avoids the pitfalls of one-pass mode, namely the tendency to compress simple scenes at very high quality and complex scenes at very low quality.
Above: graph of quantizer choice (which roughly corresponds to the encoding quality) when using default two-pass bitrate management as opposed to one-pass (with --soft-target) when encoding matrix at 300kbps. Both encodes resulted in the same bitrate. The quality of a one-pass encode varies considerably as the encoder has no way to plan ahead.
Two-pass encoding is accessed via the TH_ENCCTL_2PASS_OUT and TH_ENCCTL_2PASS_IN commands to the th_encode_ctl() interface. Two pass is thus available to any application based on libtheora; encoder_example.c has been extended to offer/illustrate the use of two-pass encoding.
One-pass bitrate management is still essential to live video streaming where a stream is being produced on the fly and transmitted via a fixed- or constrained-bandwidth channel. In these cases, one-pass rate management must strictly obey bandwidth constraints without exception.
The largest complaint with Theora's bitrate management to date (including in the Thusnelda alpha releases) was that even managed-bitrate modes had an unknown 'minimum bitrate' below which they couldn't scale and this minimum was unpredictable. At the point that Theora hit its minimum possible quantizer and lambda values (encoding only DC and minimal framing), bitrate could not drop further and rate control would violate the requested rate budget constraints.
Frame dropping is a standard way of extending a codec's 'low end' to allow bitrate lower than what the codec could otherwise acheive. Along with two-pass, I implemented frame dropping support according to Tim's design at the end of July and he further improved that implementation in the beginning of August. Note that frame dropping is currently offered with finite-buffer two-pass and one-pass only. Full-file two-pass requires some additional work to support frame dropping.
Variable frame rate support (designed and implemented by Tim) is closely related to [and shares code with] frame-dropping, but has a different purpose. In this case, we're not 'dropping' frames to save bitrate, but rather explicitly or implicitly duplicating frames in the encoder to handle input video where not every frame changes, or frames change at an irregular rate. One common example is animation where source vide may be provided at 24 or 30fps, but the 'real' framerate within the video is much lower, often as low as 4fps, and varies from scene to scene. This is especially common in anime.
In the implicit case, video is merely fed to the encoder at a fixed frame rate and it is up to the encoder to find duplicate frames, usually by determining that there's nothing new to encode. In this case, the encoder internally marks and handles these frames as duplicates (thus encoding nothing for them but a placeholder packet).
This is wasteful in once sense however; even the duplicate frames must submitted to the encoder and analyzed. In the case where the application is already aware of the actual frame rate and frame spacing, it may submit only the real frames to libTheora and declare that the submitted frame is to be duplicated some number of times.
Theora has always had the ability to use Adaptive Quantization via multiple quantization indexes per frame of video. Although Theora decoders have supported this feature for a few years now, no encoder actually used it. Tim added AQ to the Thusnelda encoder in July.

Telemetry example from clip encoded at 580kbps using 1.0 encoder, showing only a single qi in use.

Telemetry example from clip encoded at 300kbps using release candidate encoder, showing AQ/multiple quantizer indicies in use.
The current implementation uses AQ based solely on RD cost analysis, rather than based on any psychovisual criteria.
As with Adaptive Quantization, Theora added support for 4:2:2 and 4:4:4 chroma samplings to the original VP3 specification. Again, the decoder has supported this for years though no encoder produced 4:2:2 or 4:4:4 files.
diagrams of different chroma subsamplings; note that Theora uses JPEG chroma positionings.
As of June, the Thusnelda encoder supports full 4:2:2 and 4:4:4 encoding.
At the end of July, I added several new debugging 'telemetry' visualizations to make it easier to see and debug newly added encoder features. As of today, the complete list of debugging visualizations available through th_decode_ctl are:

Motion vector visualization: The arrow points in the direction of motion, the length indicates magnitude.

Macroblock mode visualization: Red blocks indicate INTRA, blue blocks indicate INTER, yellow blocks indicate GOLDEN, yellow squares indicate GOLDEN_MV, green squares indicate INTER_MV, green squares with one arrow indicate INTER_LAST, green squares with two arrows indicate INTER_LAST2, and a cluster of four green squares indicates FOURMV.

Quantizer visualization: The first number in the lower left is the base qi, the next one or two (if any) indicate auxiliary qis. Green pluses and red minuses in the frame indicate the block at that location is using the auxiliary qi greater to or less than the base qi.

Bit usage visualization: The red bar represents bit usage needed to code used/unused blocks, the green bar represents the number of bits used to code macroblock modes, the blue bar represents the number of bits used to code explicit motion vectors, the brown bar represents bits used to code quantizer choices, the gray bar represents bits used to code DC coefficients and the purple bar represents AC.
These visualizations are drawn directly into the output video at decode time and are available to any application using libTheora for decoding (note: libTheora must be built with the visualization support enabled). player_example.c illustrates the use of a few of the visualizations, and my personal Mplayer fork (complete patch here) supports all visualizations as arguments [vismbmode=X:vismv=X:visqi=X:visbits=X:visall] to the -theoradopts option. For example,
mplayer -theoradopts visqi=0x3:visbits=1 video.ogv
...would decode video.ogv while displaying the currently active quantization indexes, which blocks were using the indexes, and a bit-usage bargraph. The following:
mplayer -theoradopts visall video.ogv
...would turn on all visualizations, though having them all active is probably too much of a jumble to be useful.
In addition to the frame-dropping mentioned above, I spent some time improving the existing one-pass bitrate management. Tim's first implementation of one-pass in Thusnelda from the spring was based on a simple first order exponential follower and had the disadvantages of being prone to oscillation and not taking the bit buffer size into account in its reaction time. For these reasons, the existing code was twitchy and reacted overly quickly to even fleeting single-frame metrics changes. The time constant could not be lengthened as it caused oscillations to grow worse.

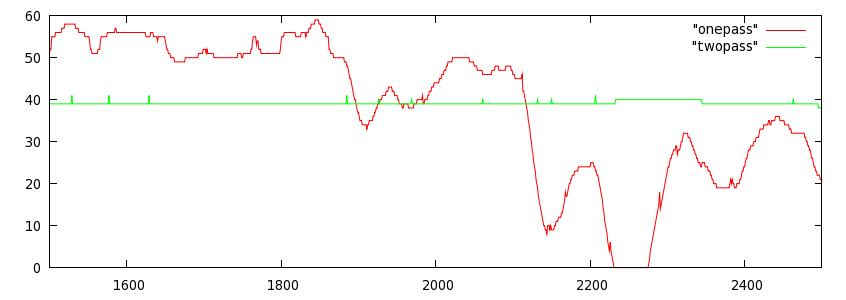
Above: one-pass qi selection in Matrix clip at 300kbps using 1.1alpha2. Note the tendency to oscillate, as well as nearly identical time behavior for two drmatically different buffer sizes. The only reason the two curves differ is the longer keyframe interval in the green curve, the only way to affect the buffer size in 1.1 alpha 2.
The improved one-pass code uses a second-order Bessel filter to track scale changes within the rate modelling. The time constant for the filter is chosen to allow a full-scale reaction within half the time of the buffer period.
Above: one-pass qi selection in Matrix clip at 300kbps using current SVN. Oscillations are gone and time behavior scales according to buffer depth.
In addition to eliminating any chance of undamped oscillation (though the qi oscillation clamping code was left in place-- just in case) it also means that the filter does not react instantaneously to temporary changes, but can still swing full scale quickly in the event of a deep trend.
Summarizing Tim's report, early SKIP allows the encoder to perform smarter mode decision as it can get better estimates of the real cost of coding in a particular mode, and also lets it avoid spending lots of time analyzing blocks it is likely to leave uncoded. Speed improvements can be as much as 17% from this alone.
The default quantization matrix replacement work, described as 'just begun' in the last update, landed in July. Specifically, the new matricies are much flatter at low bitrates, which is perceptually much more pleasing, gives better PSNR, and should reduce the excessive ringing/mosquito noise on text at very low rates. The improvement at low rate is similar to what AQ achieves at high rates.
Tim finally acheived the Holy Grail of an encode loop that is, in fact, actually a single loop. That means performing MB mode decision, transform, quantization, tokenization, reconstruction, loop filtering, and border filling for one or two super block rows in their entirety (for all three color planes). Frame data now typically enters and leaves the cache only once for each frame, far fewer than the 12 or so times required by the 1.0 encoder.
From Tim: "Simon Hosie (Gumboot)'s DC prediction optimizations for the decoder were added, and I ported them to the encoder as well. This gives a several percent speed improvement (more for older/underpowered processors like the Geode and Atom). The remaining patches (some of which give much large speed improvements) will be incorporated over the next week." The 'remaining patches' have since also been added.
The encoder and decoder, initially fully seperated to make working on the new encoder easier, were re-merged in order to share code across common operations (as the encoder by necessity must contain a complete decoder). This re-merge eliminated more than 3,000 lines of code.
This is additional useful work that has been done 'not on the official clock'.
I've extended the yuv4mpeg2 format into 'yuv4ogg' to add timing information and interleaved media such that, eg, audio and video can be placed in a single yuv4ogg stream. This allows yuv4ogg to be more useful as a 'patch cable' format for trading raw a/v data directly between applications, for example, over a pipe.
My initial main desire for yuv4ogg was to be able to more conveniently export raw data from mplayer, where it could be operated on by external filters and/or passed directly to a Theora encoder. The first use case was to export video from mplayer complete with timing information, such that VFR formats (such as WMV) could be sent to an external utility that could lock and hold A/V sync before sending off to an encoder.
[Note: several years ago I wrote similar functionality internal to mplayer which wasn't accepted into upstream. But because a good A/V sync algorithm requires a potentially large amount of buffering, something that mplayer can't really do internally, I came to the conclusion this was best implemented outside of mplayer, and so wrote an external utility far superior to my mplayer-internal version.]
At this point, I've implemented yuv4ogg input [demux] and output [via vf and af such that they can be used similar to 'tee'] support for mplayer, an initial external filter utility named y4oi [yuv4ogg interchange] that implements my external syncing and fixup ability, and yuv4ogg input support for encoder_example, currently on a branch.
Using mplayer and y4oi together to transcode with automatic, enforced A/V sync will the subject of a later blog post ;-)
At present, Adapative Quantization in Theora is performed solely according to RD cost analysis (a solid, objective means of deciding which quantizer to use). However, we're nearing the end of objective optimization in Theora and moving into a phase of subjective tuning. Adaptive Quantization is one possible place where subjective heuristics stand to improve perceived quality.
I've performed my first experiments into possible useful metrics for improving perceived quality using AQ. The initial experiment involved weighting distortion accoding the minimum 'local neighborhood' variance in a block. That is, for every pixel in a block, calculate the variance of the 3x3 neighborhood around the block (9 pixels), then use the minimum of the 64 local varances in that block as an SSD weight in qi decision making. Low variance is used to increase weighted distortion and high variance is used to reduce weighted distortion. The intent is that blocks that contain only very complex patterns are penalized as the pattern masks distortion. Blocks with very little variance are promoted as distortion is unmasked. In practice, this mostly has the effect of strongly promoting blocks that have exposed, sharp edges within them.
This code worked as intended, however the psychovisual results are inconclusive; improvement, if any, does not appear to justify the extra computational cost.
Left: Matrix clip at 300kbps using objective AQ (mainline), showing a frame of output telemetry indicating qi selection by block. The image is a link to the full clip.

Left: Matrix clip at 300kbps using variance-weighted distortion for AQ, showing a frame of output telemetry indicating qi selection by block. The image is a link to the full clip.
The release candidates show substantial PSNR improvement over 1.1alpha2, approximately doubling-again the gains that 1.1alpha2 achieved over the original Theora 1.0 mainline. Example PSNR graphs:

Left: 'Big Buck Bunny' test clip, encoded using rate managed 1.0, 1.1alpha2 and using the 1.1 release candidate with one-pass, two-pass and soft-target modes. Two pass doubles again on the alpha's improvements over 1.0.

Left: husky_cif test clip, encoded using variable bitrate 1.0, 1.1alpha2 and using the 1.1 release candidate.
Other test graphs can be found in Maik's homepage at xiph.org. Not every clip shows quite as dramatic an improvement; for example, the original Matrix test clip shows only about .6dB improvement over 1.0 at 580kbps using two-pass (compared to 1.0 variable bitrate; 1.0's managed bitrate output was atrocious on this clip).
Recall again that PSNR graphs are nearly useless for comparing two different codecs with one another or when comparing different source material. However, PSNR has been shown to correlate strongly (>98%) with perceived quality when used to measure improvements across the same codec with the same source material as we are doing here.